[ISNLP 오픈 튜토리얼] 2일차: Tensor 연산과 Perceptron
[ISNLP 오픈 튜토리얼] 2일차: Tensor 연산과 Perceptron
2일차: Tensor 연산과 Perceptron 정리
이번 2일차 수업에서는 딥러닝의 기본 단위 연산인 Tensor 연산과
퍼셉트론(Perceptron) 및 MLP 구조를 학습하고, PyTorch를 활용해 직접 구현해보았다.
이번 글에서는 내가 이해한 핵심 개념과 실습 코드 흐름을 정리한다.
1. Tensor 연산 (3강)
1-1. 텐서(Tensor) 기초
- Tensor: 3차원 이상의 행렬 (딥러닝에서는 모든 데이터 구조를 Tensor라 부름)
- 행렬곱 조건:
- 곱해지는 두 텐서의 내적 차원이 일치해야 함
- 예:
(m x k) @ (k x n) = (m x n)
- 선형 회귀(Linear Regression)를 Tensor로 표현
\(y = x_1 a + x_2 b \quad \Rightarrow \quad \mathbf{Y} = \mathbf{X} \mathbf{W} + \mathbf{b}\)
1-2. Batch Processing
- 여러 데이터를 한 번에 처리하기 위해 Batch 단위 Tensor 연산 수행
예: 3개의 데이터 $(x_1, x_2, x_3)$와 2개 파라미터 $(a,b)$ \(\mathbf{X} = \begin{bmatrix} x_1 & z_1 \\ x_2 & z_2 \\ x_3 & z_3 \end{bmatrix}_{(3,2)}, \quad \mathbf{W} = \begin{bmatrix} a \\ b \end{bmatrix}_{(2,1)}\) \(\mathbf{Y} = \mathbf{XW} \in \mathbb{R}^{3 \times 1}\)
- PyTorch에서는 scalar bias $c$를 그대로 더하면 Broadcasting으로 $(3,1)$에 확장됨
1-3. Tensor 기반 Logistic Regression
- 기존 수식: $y = \sigma(ax_1 + bx_2 + cx_3 + d)$
Tensor 표현:
\(\mathbf{Y} = \sigma(\mathbf{XW} + \mathbf{b})\)- PyTorch 구현 예시:
1
2
3
4
5
6
7
8
9
10
import torch
import torch.nn.functional as F
X = torch.randn(3, 3) # (batch_size, in_features)
W = torch.randn(3, 1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
y_pred = torch.sigmoid(X @ W + b) # (3,1)
loss = F.binary_cross_entropy(y_pred, torch.tensor([[1.],[0.],[1.]]))
loss.backward()
2. Perceptron & MLP (4강)
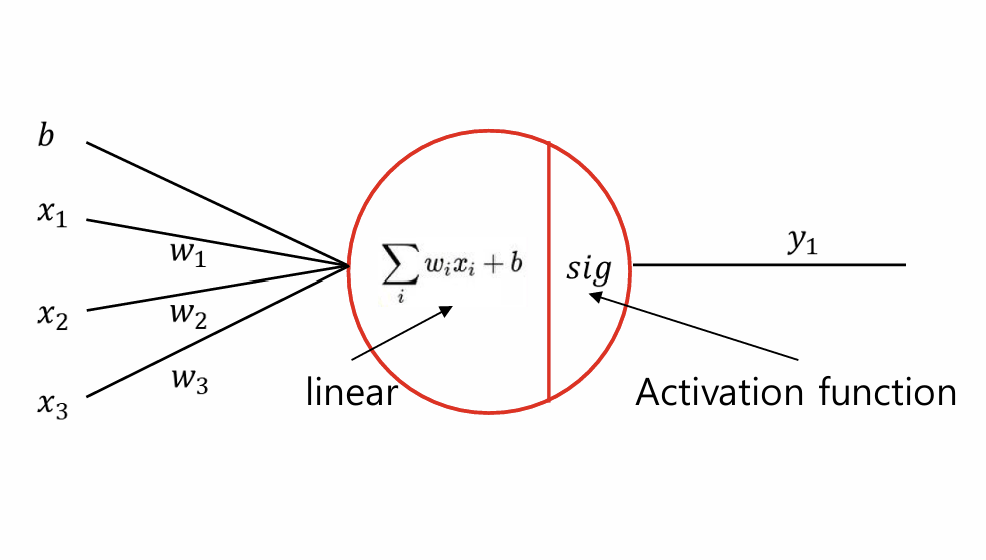
2-1. 퍼셉트론(Perceptron)
- 수학적 표현:
\(y = f(\mathbf{W} \mathbf{X} + b)\)- $f$: 활성화 함수(Activation Function, 예: Sigmoid, ReLU)
- 특징:
- 선형 결합 + 비선형 변환
- 활성화 함수로 모델의 표현력 증가
2-2. 다층 퍼셉트론(MLP)
- 퍼셉트론 여러 개를 쌓아 Hidden Layer ≥ 1이면 MLP
- 입력/출력 차원에 맞게 행렬곱 수행
- 다층 구조에서는 행렬 크기(shape) 불일치로 에러가 자주 발생
- 실습 중간중간
tensor.size()출력해서 확인 필수
- 실습 중간중간
2-3. PyTorch nn.Linear를 이용한 구현
- 이진 분류 Logistic Regression
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
import torch.nn as nn
import torch.nn.functional as F
linear = nn.Linear(in_features=3, out_features=1)
optimizer = torch.optim.SGD(linear.parameters(), lr=0.01)
for epoch in range(100):
y_pred = torch.sigmoid(linear(X))
loss = F.binary_cross_entropy(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
- 다중 클래스 분류(Multi-class)
- Output dimension = Class 수
torch.nn.functional.cross_entropy사용
3. 오늘 배운 내용 정리
3-1. 중요하게 본 내용
- 모델이 복잡해질수록 텐서의 크기(shape) 관리가 중요
- 학습 과정에서
tensor.size()를 주석과 함께 확인하면 디버깅에 큰 도움
3-2. 배운 점
- Linear/Logistic Regression을 Tensor 연산으로 일반화할 수 있음을 이해
- Batch Processing과 Broadcasting의 작동 원리를 파이토치로 확인
nn.Linear를 이용해 손쉽게 퍼셉트론과 로지스틱 회귀를 구현 가능
3-3. 느낀 점
- 퍼셉트론 자체는 이미 익숙했지만,
텐서 크기 문제와 shape 불일치 에러를 피하려면
중간중간.size()로 체크하고 주석을 남기는 습관이 필요함을 깨달았다.
4. 참고 자료
다음 포스팅에서는 3일차: PyTorch Utils와 Embedding 기초 내용을 정리할 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.