[ISNLP 오픈 튜토리얼] 3일차: PyTorch Utils와 Embedding 기초
[ISNLP 오픈 튜토리얼] 3일차: PyTorch Utils와 Embedding 기초
3일차: PyTorch Utils와 Embedding 기초 정리
이번 3일차 수업에서는 PyTorch를 활용한 데이터 처리 유틸리티와
자연어 처리를 위한 임베딩(Embedding)을 학습했다.
이 날부터 본격적으로 NLP 관련 주제가 등장하여
자연어 처리에 대한 흥미를 크게 느낄 수 있었다.
1. PyTorch Utils
1-1. Dataset과 DataLoader
torch.utils.data.Dataset- 개별 데이터를 Tensor로 변환해 반환
__len__→ 전체 데이터 길이__getitem__→ 개별 데이터/라벨 반환
torch.utils.data.DataLoader- Dataset을 받아 batch 단위로 묶어주는 클래스
- 미니배치 학습, 셔플링(shuffle), 병렬 로딩 지원
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from torch.utils.data import Dataset, DataLoader
import torch
class MyDataset(Dataset):
def __init__(self, data, labels):
self.data = torch.tensor(data, dtype=torch.float32)
self.labels = torch.tensor(labels, dtype=torch.long)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.labels[idx]
dataset = MyDataset([[1,2],[3,4],[5,6]], [0,1,0])
loader = DataLoader(dataset, batch_size=2, shuffle=True)
for x, y in loader:
print(x, y)
1-2. nn.Module과 모델 정의
- PyTorch 모델은
nn.Module을 상속받아 작성 __init__: 레이어 선언 (예:nn.Linear)forward: 입력 Tensor → 출력 Tensor 변환 (feed forward 과정)
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch.nn as nn
import torch.nn.functional as F
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
1-3. Loss Function과 Optimizer
- Loss Function
nn.MSELoss: 회귀 문제nn.CrossEntropyLoss: 다중 클래스 분류 (Softmax 내장)
- Optimizer
torch.optim.SGD,torch.optim.Adam등optimizer.step()으로 파라미터 업데이트
1-4. GPU 사용
- 모든 Tensor와 모델을 같은 디바이스로 올려야 함
tensor.to("cuda")또는model.cuda()사용
1
2
3
4
5
6
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MyModel().to(device)
for x, y in loader:
x, y = x.to(device), y.to(device)
pred = model(x)
2. Embedding 기초
2-1. 텍스트 데이터를 수치화하는 방법
- Tokenization
- 문장 → 단어 시퀀스
- 예:
"I am student"→["I", "am", "student"]
- Word to Index Mapping
- 사전(Vocab) 구성 후 단어를 정수 인덱스로 매핑
- 예:
["I", "am", "student"]→[11, 2, 523]
- One-hot Encoding
- 단어를 단순한 희소 벡터(sparse vector)로 변환
- 비효율적이므로 실제 딥러닝에서는 잘 쓰이지 않음
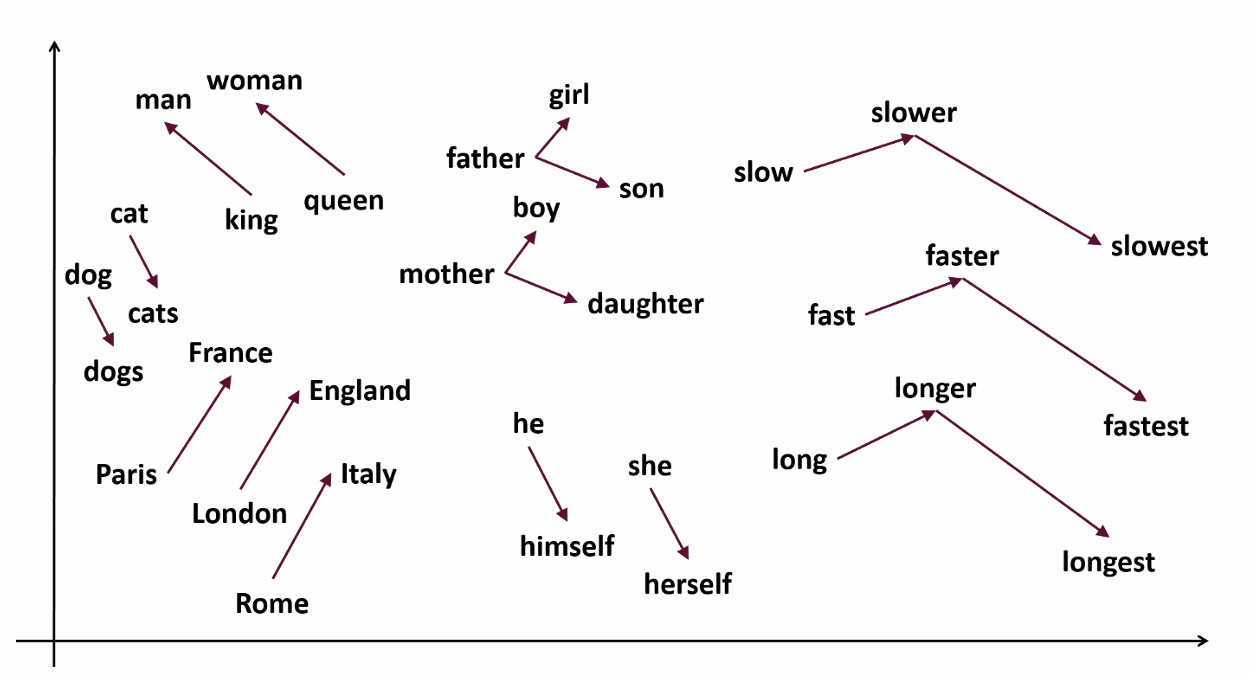
2-2. Dense Embedding과 Word2Vec
- Dense Representation
- 희소 벡터 대신 연속적인 실수 벡터로 단어 의미를 표현
- Word2Vec
- Skip-gram: 중심 단어 → 주변 단어 예측
- CBOW: 주변 단어 → 중심 단어 예측
- 학습된 Embedding Vector는 단어 간 의미적 유사성을 반영
2-3. PyTorch의 nn.Embedding
nn.Embedding(num_words, embedding_dim)- 학습 가능한 Embedding Table 생성
- 입력: 단어 인덱스 시퀀스 → 출력: 해당 단어 벡터
- 간단한 예시:
1
2
3
4
5
6
7
import torch
import torch.nn as nn
embedding = nn.Embedding(num_embeddings=1000, embedding_dim=64)
input_ids = torch.tensor([3, 2, 1, 4]) # 단어 인덱스
vectors = embedding(input_ids)
print(vectors.shape) # (4, 64)
2-4. 간단한 문장 분류 모델
- 각 단어를 Embedding Vector로 변환
- Max Pooling → Sentence Embedding
- MLP로 분류
1
2
3
4
5
6
7
8
9
10
class SentenceClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, num_classes):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.fc = nn.Linear(embed_dim, num_classes)
def forward(self, x):
embeds = self.embedding(x) # (batch, seq_len, embed_dim)
pooled, _ = torch.max(embeds, 1) # Max pooling
return self.fc(pooled)
3. 오늘 배운 내용 정리
3-1. 중요하게 본 내용
- PyTorch의 Dataset/DataLoader로 배치 처리 구현
nn.Module로 모델 구조 정의와 학습 파이프라인 구축- Sparse One-hot → Dense Embedding 전환의 중요성
nn.Embedding과 Word2Vec 개념적 연결
3-2. 배운 점
- 그동안 개념으로만 알던 Word2Vec / Skip-gram / CBOW를
PyTorch로 구현하며 이해가 완성됨 - 실제 임베딩 테이블 학습 과정을 체험하면서
NLP 모델의 입력 준비 과정을 명확히 이해
3-3. 느낀 점
- 이전에는 임베딩을 잘 이해하지 못했는데
이번 실습을 통해 퍼즐이 맞춰지듯 이해할 수 있었음 - 이때부터 자연어 처리에 본격적인 흥미를 느끼게 되었음
4. 참고 자료
다음 포스팅에서는 4일차: RNN과 LSTM 기초 내용을 정리할 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.