[ISNLP 오픈 튜토리얼] 4일차: RNN과 LSTM 기초
[ISNLP 오픈 튜토리얼] 4일차: RNN과 LSTM 기초
4일차: RNN과 LSTM 기초 정리
이번 4일차 수업에서는 순서 정보(sequence information)를 학습할 수 있는
RNN(Recurrent Neural Network)과 LSTM(Long Short Term Memory) 구조를 학습했다.
이날 실습을 통해 모델이 과거 정보를 기억하고 활용한다는 개념을 처음으로 체감할 수 있었다.
1. RNN (Recurrent Neural Network)
1-1. 순서 정보의 중요성
- 단어의 순서가 바뀌면 문장의 의미도 달라진다.
- 기존의 Perceptron, Max Pooling 기반 모델은 순서 정보를 학습하기 어려움.
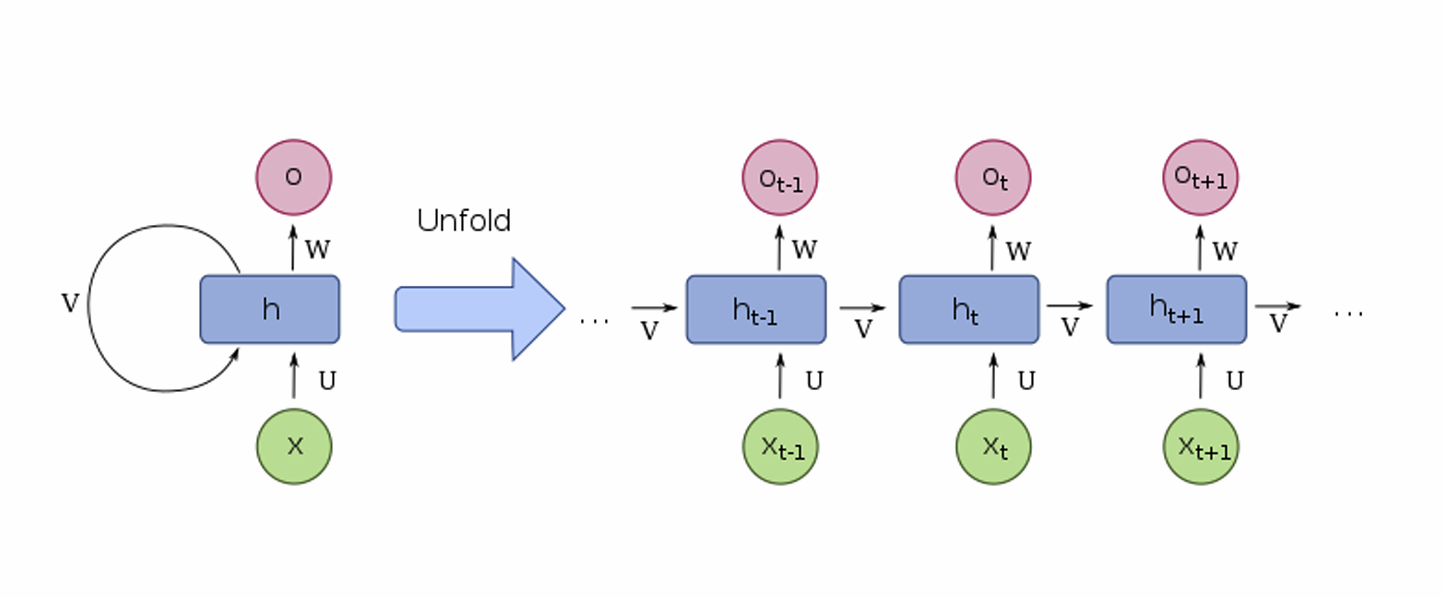
- RNN은 이전 상태(hidden state)와 현재 단어의 embedding을 이용해 순서 정보를 학습한다.
1-2. RNN의 동작 원리
- 입력: $x_t$ (t번째 단어 embedding)
- 출력: $h_t$ (t번째 hidden state)
- 이전 hidden state $h_{t-1}$를 사용해 과거 정보를 누적.
- 마지막 hidden state를 문장 표현(sentece embedding)으로 활용 가능.
1-3. PyTorch에서의 RNN 사용
1
2
3
4
5
6
7
8
9
10
import torch
import torch.nn as nn
rnn = nn.RNN(input_size=128, hidden_size=64, batch_first=True)
x = torch.randn(32, 10, 128) # (batch, seq_len, input_size)
output, hidden = rnn(x)
print(output.shape) # (32, 10, 64) 모든 time step의 hidden state
print(hidden.shape) # (1, 32, 64) 마지막 hidden state
1-4. RNN의 한계: 장기 의존성 문제
- 시퀀스가 길어질수록 앞쪽 단어의 정보가 소실됨.
- 뒤쪽 토큰(Padding 포함)의 영향력이 커짐.
2. 문장 뒤집기(Sequence Reversal)
2-1. 왜 문장을 뒤집는가?
- 일반적으로 NLP 실습에서는 시퀀스를 맞추기 위해 뒤에
<PAD>를 붙인다.1
["I", "am", "student", "<PAD>", "<PAD>"]
- RNN은 뒤쪽 단어의 hidden state를 더 강하게 반영하므로
마지막 hidden state가 의미 없는<PAD>정보에 덮일 수 있다. - 이를 해결하기 위해 문장을 뒤집어 입력하면:
1
["<PAD>", "<PAD>", "student", "am", "I"]
- 실제 단어들이 시퀀스의 뒤쪽으로 이동
- 마지막 hidden state가 유효 단어 정보를 최대로 반영
- Padding 영향 최소화
2-2. PyTorch 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import torch
import torch.nn as nn
# batch_size=2, seq_len=5
inputs = torch.tensor([
[1, 2, 3, 0, 0], # "I am student <PAD> <PAD>"
[4, 5, 6, 7, 0] # "He likes playing football <PAD>"
])
# 문장 뒤집기 (dim=1이 시퀀스 축)
inputs_reversed = torch.flip(inputs, dims=[1])
print(inputs_reversed)
# tensor([[0, 0, 3, 2, 1],
# [0, 7, 6, 5, 4]])
embedding = nn.Embedding(100, 16)
rnn = nn.RNN(16, 32, batch_first=True)
x = embedding(inputs_reversed)
output, hidden = rnn(x)
print(hidden.shape) # (1, batch_size, hidden_size)
효과
- 마지막 hidden state가 실제 단어 정보를 더 많이 포함
- Padding 영향 감소
- 장기 의존성 문제를 어느 정도 완화
⚡ 최근에는 양방향 RNN(Bi-LSTM)이나 Transformer 계열 모델을 사용하면
별도의 뒤집기 없이도 양방향 정보를 학습 가능
3. LSTM (Long Short Term Memory)
3-1. LSTM의 아이디어
- RNN의 Long-term dependency 문제를 해결하기 위해 설계된 구조
- 장기 기억(Cell state)과 단기 기억(Hidden state)를 분리
- 게이트(Gate) 구조를 통해 기억 유지/삭제를 제어
3-2. LSTM의 게이트 구조
- Forget Gate: 과거 정보를 얼마나 지울지 결정
- Input Gate: 새로운 정보를 얼마나 추가할지 결정
- Output Gate: 최종 출력으로 얼마나 보낼지 결정
\(f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)\) \(i_t = \sigma(W_i [h_{t-1}, x_t] + b_i)\) \(\tilde{C}_t = \tanh(W_C [h_{t-1}, x_t] + b_C)\) \(C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t\) \(h_t = o_t \odot \tanh(C_t)\)
3-3. PyTorch에서의 LSTM 사용
1
2
3
4
5
6
7
8
9
10
11
import torch
import torch.nn as nn
lstm = nn.LSTM(input_size=128, hidden_size=64, batch_first=True)
x = torch.randn(32, 10, 128)
output, (h_n, c_n) = lstm(x)
print(output.shape) # (32, 10, 64)
print(h_n.shape) # (1, 32, 64) 마지막 hidden state
print(c_n.shape) # (1, 32, 64) 마지막 cell state
4. 오늘 배운 내용 정리
4-1. 중요하게 본 내용
- RNN은 이전 hidden state를 이용해 순서 정보를 학습
- 시퀀스가 길어질수록 정보 소실 문제(장기 의존성) 발생
- 문장 뒤집기로 Padding 영향을 줄이고 성능 개선 가능
- LSTM은 게이트 구조로 장기 기억과 단기 기억을 제어
4-2. 배운 점
- RNN과 LSTM의 동작 원리를 수식과 코드로 이해할 수 있었음
- 문장 뒤집기 기법을 통해 Padding 문제와 정보 소실 문제를 직접 체감
- LSTM이 RNN의 한계를 극복하는 구조적 특징을 명확히 이해
4-3. 느낀 점
- hidden state로 순서 정보를 학습한다는 것이 신기했음
- Padding 때문에 성능이 떨어질 수 있고
문장을 뒤집으면 성능이 개선되는 점이 흥미로웠음 - LSTM의 게이트 구조로 기억을 조절하는 아이디어가 인상적이었음
- RNN과 LSTM을 직접 실습해보면서 이해도가 크게 높아짐
5. 참고 자료
다음 포스팅에서는 5일차: Seq2Seq 기초에 대한 내용을 정리할 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.