[ISNLP 오픈 튜토리얼] 5일차: Seq2Seq와 문장 생성
[ISNLP 오픈 튜토리얼] 5일차: Seq2Seq와 문장 생성
5일차: Seq2Seq와 문장 생성
이번 5일차 수업에서는 Sequence-to-Sequence (Seq2Seq) 구조를 중심으로,
자연어 문장 생성(Task: 기계번역, 문장 정렬 등)의 기본 개념과 PyTorch 구현을 학습했다.
이전까지는 분류(Classification) 위주였지만,
이번에는 문장을 생성하는 문제를 다루면서 기존 지식이 유기적으로 연결되었다.
1. Seq2Seq 기본 개념
1-1. 문장 생성과 분류의 차이
- 분류(Classification): 입력 문장 → 레이블
- 뉴스 분류, 스팸 필터, 품사 태깅(POS Tagging)
- 생성(Generation): 입력 문장 → 출력 문장
- 기계 번역, 요약, 대화 시스템, 질의응답
1-2. 기존 RNN 번역의 한계
- Source와 Target의 단어 수 불일치
- 번역에 필요한 단어가 아직 입력되지 않은 경우 발생
- 언어마다 어순이 달라 시점 불일치 문제
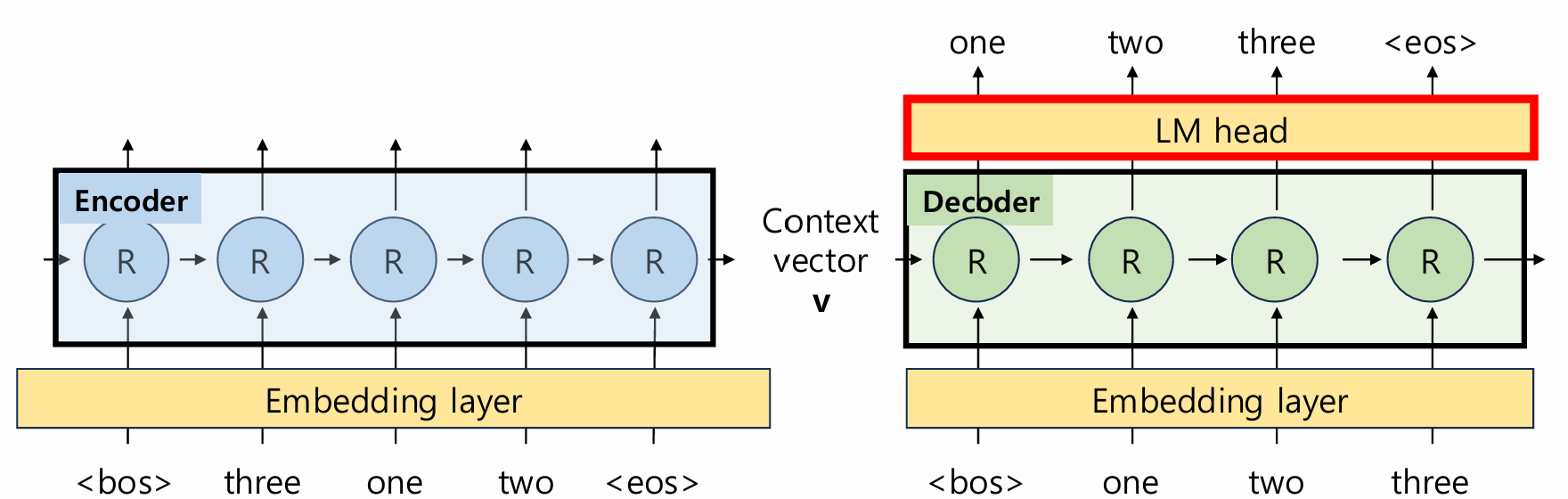
1-3. Seq2Seq 구조
- Encoder: Source 문장을 RNN/LSTM으로 처리해 Context Vector 생성
- Decoder: Context Vector를 받아 Target 문장을 Auto-Regressive하게 생성
- Teacher Forcing: 학습 시 정답 토큰을 Decoder 입력으로 사용
- LM Head (nn.Linear): 마지막 hidden state → 단어 확률 분포
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import torch
import torch.nn as nn
class Seq2Seq(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.encoder = nn.RNN(embed_dim, hidden_dim, batch_first=True)
self.decoder = nn.RNN(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size) # LM Head
def forward(self, src, tgt):
src_emb = self.embedding(src)
tgt_emb = self.embedding(tgt)
_, hidden = self.encoder(src_emb)
output, _ = self.decoder(tgt_emb, hidden)
return self.fc(output)
1-4. Auto-Regressive 생성 과정
<bos>토큰 입력 → 첫 번째 단어 예측- 이전에 예측된 단어를 다음 입력으로 사용
<eos>토큰을 만나면 종료
1
2
Input : I am a student .
Output: 저는 학생 입니다 .
1-5. 성능 평가
- BLEU Score: n-gram 정답률 기반 문장 유사도
- 연속된 단어 정확도가 중요 → 생성 모델 평가에 적합
2. 오늘 배운 내용 정리
2-1. 중요하게 본 내용
- Seq2Seq의 Encoder-Decoder 구조와 Auto-Regressive 디코딩
- Source-Target 시퀀스 길이 불일치, 시점 불일치 문제 해결
- LM Head(
nn.Linear)가 단어 예측 확률 분포를 만드는 역할
2-2. 배운 점
- 이전에 배운 RNN/LSTM, Embedding, nn.Linear가
Seq2Seq 모델 내부에서 유기적으로 활용됨을 이해 - Teacher Forcing과 Auto-Regressive를 통해
생성 모델의 학습과 추론 과정 차이를 명확히 이해
2-3. 느낀 점
- Transformer를 공부할 때 궁금했던 왜 인코더/디코더 구조인지가 이해됨
- LM Head를 보며 “기초가 이렇게 쓰이는구나”를 체감
- 괜히 기초가 중요한 게 아니라는 걸 다시 한 번 느낀 수업
3. 참고 자료
다음 포스팅에서는 6일차: Attention 기초를 정리할 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.