[ISNLP 오픈 튜토리얼] 6일차: Attention과 문장 생성 품질 향상
[ISNLP 오픈 튜토리얼] 6일차: Attention과 문장 생성 품질 향상
6일차: Attention과 문장 생성 품질 향상
이번 6일차 수업에서는 Seq2Seq 모델에 Attention을 적용해
문장 생성 품질을 개선하는 방법을 학습했다.
기존 RNN/LSTM 기반 Seq2Seq의 한계를 극복하고,
문장 내 중요한 단어에 더 집중(Attend)하여 자연스러운 문장을 생성할 수 있었다.
1. Attention 개념
1-1. Seq2Seq의 한계
- Context Vector는 Encoder의 마지막 hidden state 하나만 사용
- 긴 문장에서는 앞쪽 단어 정보 소실(Long-term Dependency) 문제 발생
- Decoder 단계별로 어떤 단어가 중요한지 구분하지 못함
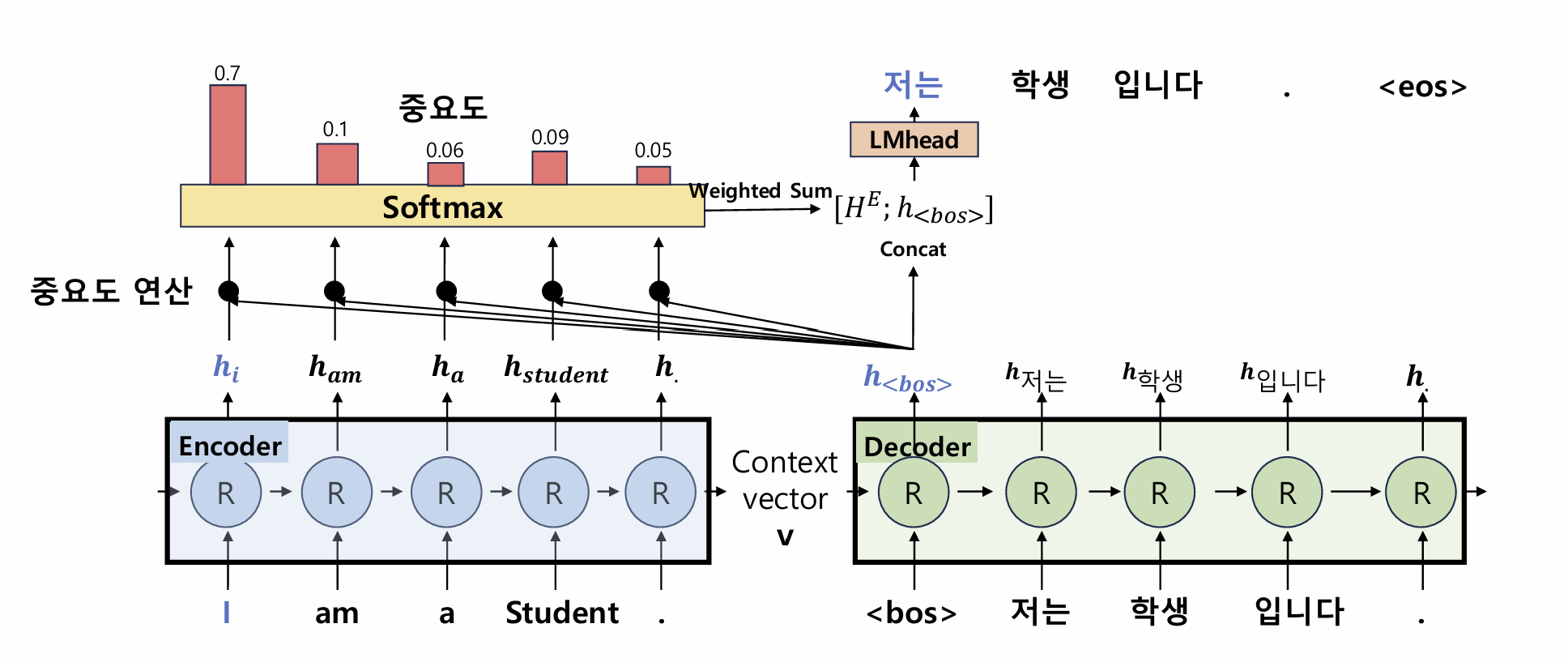
1-2. Attention의 등장
- Decoder의 현재 hidden state와 Encoder의 모든 hidden state 비교
- 중요 단어에 높은 가중치(Attention Weight) 부여
- Weighted Sum을 통해 더 풍부한 Context Vector 생성
1-3. Attention 계산 과정
- Score 계산: Decoder hidden state와 모든 Encoder hidden state 유사도 계산
- Dot Product, Cosine Similarity 등
- Softmax 정규화: Attention Weight 생성
- Weighted Sum: Encoder hidden state의 가중합으로 Context Vector 생성
- Concat 후 LM Head:
[WeightedSum; DecoderHidden] → Linear → Softmax
수식으로 표현하면 다음과 같다.
\[AttentionWeight = softmax(h_{dec} \cdot H_{enc}^T)\] \[H_E = AttentionWeight \cdot H_{enc}\] \[y_t = LMHead([H_E; h_{dec}])\]1-4. PyTorch 구현 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import torch
import torch.nn as nn
import torch.nn.functional as F
class AttentionSeq2Seq(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.encoder = nn.RNN(embed_dim, hidden_dim, batch_first=True)
self.decoder = nn.RNN(embed_dim, hidden_dim, batch_first=True)
self.attn = nn.Linear(hidden_dim*2, 1)
self.fc = nn.Linear(hidden_dim*2, vocab_size) # LM Head
def forward(self, src, tgt):
src_emb = self.embedding(src)
tgt_emb = self.embedding(tgt)
enc_out, hidden = self.encoder(src_emb)
dec_out, _ = self.decoder(tgt_emb, hidden)
# Attention 계산
attn_weights = torch.bmm(dec_out, enc_out.transpose(1, 2))
attn_weights = F.softmax(attn_weights, dim=-1)
context = torch.bmm(attn_weights, enc_out)
concat = torch.cat([dec_out, context], dim=-1)
output = self.fc(concat)
return output
2. 오늘 배운 내용 정리
2-1. 중요하게 본 내용
- Seq2Seq + Attention으로 문장 생성 품질을 향상시킬 수 있음
- Weighted Sum을 통해 시점별로 중요한 단어에 집중
- LM Head의 입력 차원이 hidden*2로 확장됨을 이해
2-2. 배운 점
- Attention을 적용하면 확률이 높은 특수 토큰 반복 문제를 완화할 수 있음
- 시퀀스 내 중요한 단어(고유 명사 등)를 잘 인식하면
문장 품질이 크게 향상됨
2-3. 느낀 점
- 실제 실습에서 문장 생성 품질이 향상된 것이 인상적이었음
- NER(BIO 태깅) 같은 개념이 왜 필요한지 체감할 수 있었음
→ 중요한 단어를 인식하고 활용하면 품질이 크게 향상 - 문제 해결을 위한 AI 방법론의 중요성을 느꼈고,
더 다양한 방법론을 공부하고 싶어짐
3. 참고 자료
- Bahdanau et al., 2015. Neural Machine Translation by Jointly Learning to Align and Translate
- PyTorch nn.RNN
- PyTorch nn.MultiheadAttention
다음 포스팅에서는 7일차: Transformer와 Self-Attention을 정리할 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.