[ISNLP 오픈 튜토리얼] 7일차: Transformer와 Self-Attention
[ISNLP 오픈 튜토리얼] 7일차: Transformer와 Self-Attention
7일차: Transformer와 Self-Attention
이번 7일차 수업에서는 Transformer 구조와 Self-Attention 메커니즘을 학습했다.
드디어 최신 NLP 모델의 핵심인 Transformer를 다루게 되어 매우 흥미로웠다.
1. Transformer 기본 개념
1-1. Transformer의 등장 배경
- RNN/LSTM 기반 Seq2Seq 모델은 순차적 연산으로 병렬화가 어려움
- Transformer는 Attention 메커니즘만으로 시퀀스를 처리 → 병렬화 가능
- 대신 순서 정보가 사라지므로 Positional Encoding으로 위치 정보 보완
1-2. Self-Attention 상세 설명
Self-Attention은 문장 내 각 단어가 다른 단어들과 어떤 관련이 있는지를 계산하는 메커니즘이다.
Transformer의 핵심으로, Query(Q), Key(K), Value(V) 3가지 벡터를 사용한다.
1) Q, K, V 정의
- Query (Q): 현재 단어가 “어떤 정보를 찾고 싶은지”를 나타냄
- Key (K): 각 단어가 “내가 가진 정보는 이런 거야”라고 제공하는 식별자
- Value (V): 실제 단어 의미 정보(Embedding)
예시) 문장 "I love NLP"에서
- Q:
"love"가 어떤 단어와 관계를 맺을지 확인하려는 질문 - K:
"I","love","NLP"각각의 특징 - V: 단어의 실제 의미 벡터
2) 유사도(Score) 계산
- Query와 모든 Key의 유사도를 계산 → Attention Score
- 일반적으로 Dot Product 사용 \(score(Q,K) = QK^T\)
3) Softmax 정규화
- Score를 Softmax로 변환 → Attention Weight
- 각 단어가 현재 단어에 얼마나 중요한지 확률화
4) Weighted Sum (Context Vector)
Attention Weight와 Value를 곱해 합산 → 문맥(Context) 생성 \(Attention(Q,K,V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)
현재 단어는 문장 전체에서 중요한 단어들의 정보를 가중합으로 흡수
5) Self-Attention의 직관
"나는 밥을 먹었다"에서"먹었다"의 Query는"밥"에 높은 Attention Weight를 가짐- 문장 전체 문맥을 반영하여
"먹었다"벡터가 강화됨 - 이 과정을 모든 단어에 대해 수행 → 문장 전체 관계를 한 번에 학습
1-3. Positional Encoding
- Self-Attention은 순서를 구분하지 못함 → 위치 정보를 추가
- Sinusoidal Positional Encoding \(PE_{(pos,2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)\) \(PE_{(pos,2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)\)
1-4. Multi-Head Self-Attention
- 단어 간 관계를 다양한 관점에서 학습
- $h$개의 Head를 병렬로 계산 후 concat
- 문법적/의미적 관계를 동시에 학습 가능
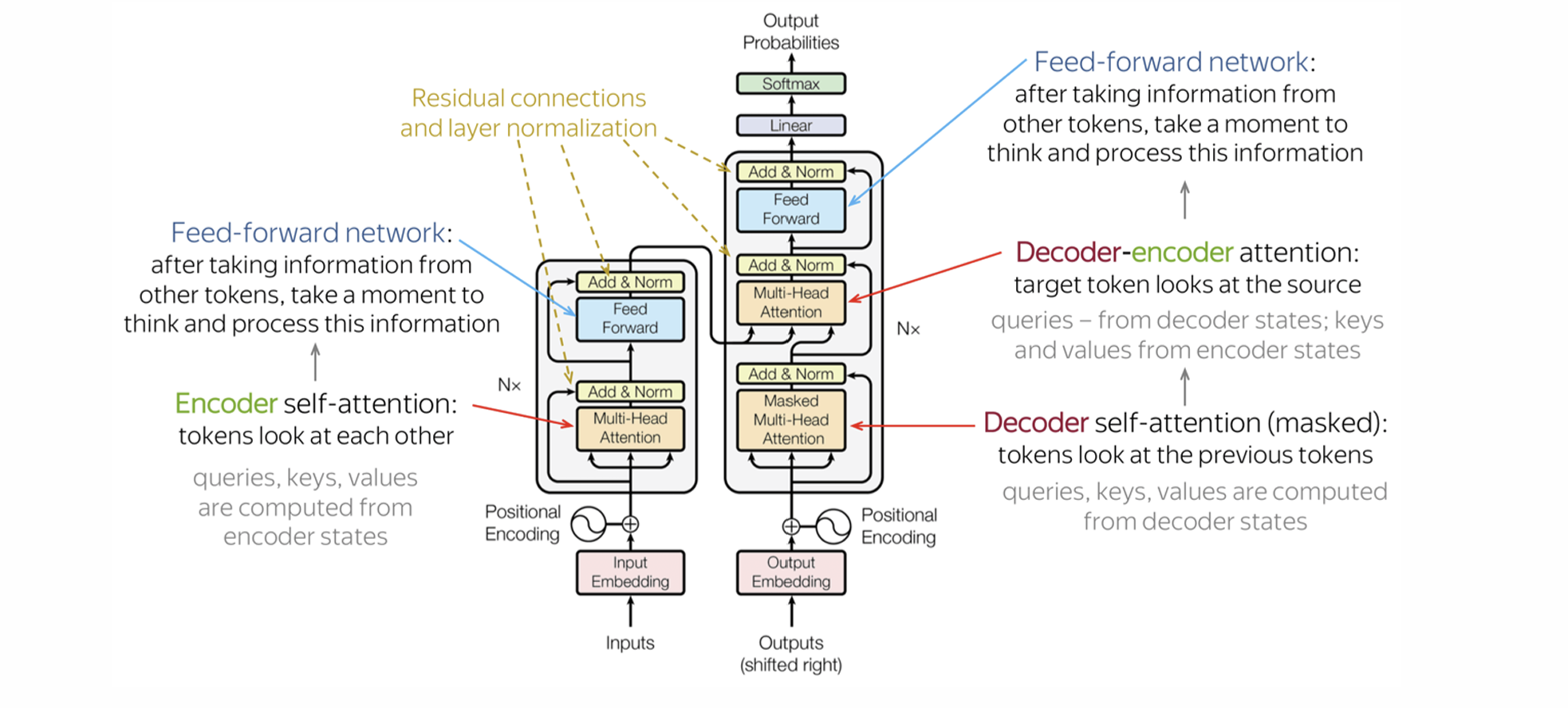
1-5. Transformer 구조
- Encoder
- Self-Attention + Feed Forward Network
- Decoder
- Masked Self-Attention + Encoder-Decoder Attention
- Auto-Regressive 문장 생성
- LM Head
- 마지막 hidden state를 단어 확률 분포로 변환
1-6. PyTorch Self-Attention 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleSelfAttention(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.W_Q = nn.Linear(embed_dim, embed_dim)
self.W_K = nn.Linear(embed_dim, embed_dim)
self.W_V = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
Q, K, V = self.W_Q(x), self.W_K(x), self.W_V(x)
scores = torch.bmm(Q, K.transpose(1,2)) / (x.size(-1) ** 0.5)
weights = F.softmax(scores, dim=-1)
return torch.bmm(weights, V)
2. 오늘 배운 내용 정리
2-1. 중요하게 본 내용
- Transformer는 RNN 없이 Attention만으로 문맥을 학습
- Self-Attention은 Query, Key, Value를 통해 단어 간 관계를 학습
- Positional Encoding으로 순서 정보 보완
2-2. 배운 점
- Transformer가 병렬화 가능하면서 문맥을 학습하는 원리를 이해
- Self-Attention의 Q/K/V 메커니즘과 Weighted Sum 과정을 명확히 이해
- Sinusoidal Positional Encoding을 통해 순서 정보까지 반영 가능
2-3. 느낀 점
- 드디어 Transformer를 배우게 되어 무척 설레었다
- Self-Attention과 Positional Encoding의 설계 철학이 인상적이었다
- 현대 NLP 모델이 왜 Transformer를 기반으로 하는지 체감할 수 있었다
3. 참고 자료
- Vaswani et al., 2017. Attention is All You Need
- PyTorch nn.MultiheadAttention
- Sinusoidal Positional Encoding 설명
다음 포스팅에서는 8일차: HuggingFace와 Pre-Trained Model에 대해 정리할 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.