[한국 전통주 RAG] 3편: 데이터 전처리와 정리
한국 전통주 RAG 프로젝트 3편: 데이터 전처리와 정리
HTML을 파싱해서 구조화된 JSON을 얻었지만, 그대로는 RAG에서 쓰기엔 부족했다.
HTML에서 최대한 많은 정보를 추출하기 위해 다양한 데이터를 추출하다 보니 불필요한 데이터도 많이 섞여있고
가장 중요한 텍스트에도 불필요한 기호가 포함되거나 단계가 중복되거나 단위가 정규화 되지 않았다는 문제가 있었다.
그래서 본격적으로 데이터 전처리 파이프라인을 구축하기로 했다.
1. 데이터 확인과 문제점
앞서 말했듯 일부 기록에는 여전히 특수 기호와 불필요한 문구가 남아 있었다.
그리고 말이나 되 같은 현대인에게 익숙하지 않은 단위가 일관되지 않게 쓰이고 있었다.
Retrieval 성능을 높이려면, 이러한 부분은 개선이 필요하다고 생각했다.
그렇게 코드를 작성하던 도중 이런 생각이 들었다.
“어차피 고생해서 파싱하고 규격화하는 김에, 아예 이 전처리된 데이터셋을 공유하면 어떨까?”
다른 사람들이 내가 전처리한 데이터셋을 활용해 프로젝트를 진행한다면 한국의 전통주를 더 널리 알릴 수 있을 것이다.
데이터 공유는 평소에 자주 이용하던 사이트인 Kaggle에서 진행하기로 하였다.
Kaggle은 글로벌 사이트임으로 전처리를 하는 김에 영문 라벨까지 붙여 국제적으로도 이해 가능한 데이터셋을 만들기로 했다.
한국어 카테고리만 있으면 외국인 연구자가 쓰기 힘들기 때문이다.
그래서 발효주 → Fermented Liquor, 누룩 → Fermentation Starter 같은 식으로 영문 라벨을 매핑했다.
1
2
3
4
5
6
7
8
9
10
11
LEVEL1_EN = {
"발효주": "Fermented Liquor",
"증류주": "Distilled Liquor",
"과하주": "Fortified Liquor",
"혼성주": "Blended Liquor",
"누룩": "Fermentation Starter",
"기타": "Other",
}
def map_en_level(k: str) -> str:
return LEVEL1_EN.get(k) or LEVELX_EN.get(k) or k
이제 한국어를 몰라도 카테고리 구조를 파악할 수 있을 것이다.
2. 파생치 생성
코드에서는 단순한 정규화만 하는 게 아니라 미래의 데이터 활용을 위해 다양한 파생치도 계산했다.
- 총 쌀/물/누룩 사용량 (
rice_total_mal,water_total_L,nuruk_total_doi) - 비율 (
water_per_rice_mal,yield_per_rice_mal) - 공정 플래그 (
uses_nuruk,hot_mixing,cold_mixing) - 텍스트 통계 (
text_len_chars,has_hanja,has_digits)
1
2
3
4
5
6
7
8
9
derived = {
"rice_total_mal": rice_total_mal,
"water_total_L": water_total_L,
"nuruk_total_doi": nuruk_total_doi,
"uses_nuruk": uses_nuruk,
"hot_mixing": hot_mixing,
"cold_mixing": cold_mixing,
"text_len_chars": text_len_chars(full_text_for_stats),
}
이런 파생치는 Retrieval 시 “조건 기반 검색”이나 “통계적 분석”을 가능하게 할것이다.
3. Kaggle 공개
이 과정을 거쳐 완성된 데이터셋을 Kaggle에 공개했다.
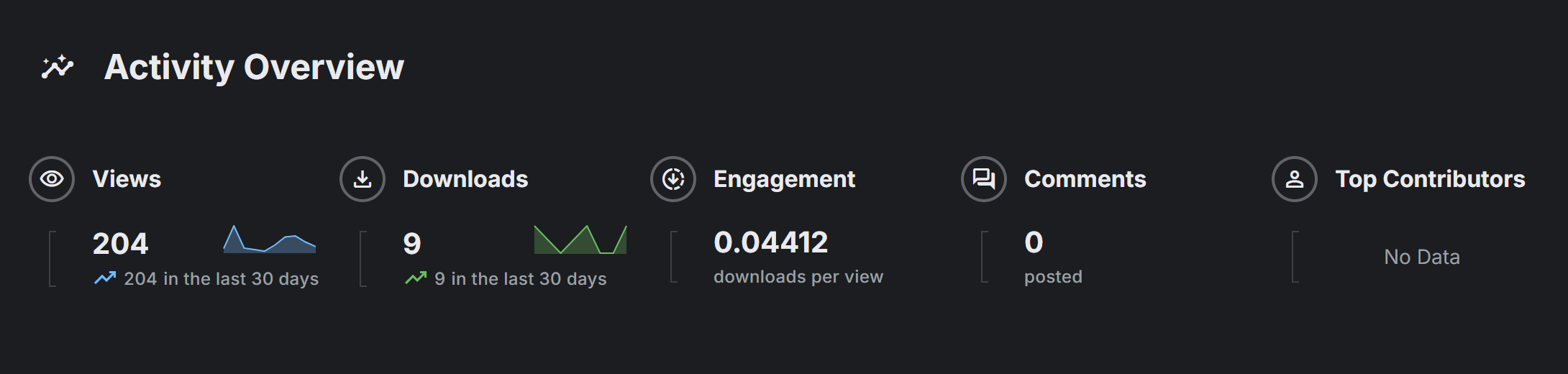
캐글 방문자 숫자 스크린 샷
Korean Traditional Liquor Dataset on Kaggle
공유 후 조회수가 늘어나는 걸 보니 꽤 뿌듯했다.
데이터셋 하나로 한국 전통문화를 해외에도 알릴 수 있다는 게 큰 의미였다.
업데이트: Hugging Face에도 공개 (2025-09-02)
Kaggle 공개 이후, 동일 데이터셋을 Hugging Face Datasets에도 배포했다.
연구자들이 datasets 라이브러리로 바로 불러오고, 버전/체크섬을 통해 재현성을 더 쉽게 확보할 수 있도록 구성했다.
Korean Traditional Liquor Dataset on Hugging Face
- 라이선스는 소스 사이트와 동일하게 CC BY-NC-SA 2.0 (KR) (원 출처 표기/비영리/동일조건)로 표시해뒀다.
Quick Start
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from datasets import load_dataset
ds = load_dataset(
"Jaeuk-Han/korean-traditional-liquor-dataset",
data_files={
"chunks": "sool_chunks.jsonl",
"docs": ["sool_docs.parquet", "sool_docs.csv"],
"steps": ["sool_steps.parquet", "sool_steps.csv"], # optional
}
)
chunks = ds["chunks"]
docs = ds.get("docs")
steps = ds.get("steps")
---
## 4. 중복 chunk_id 문제
Retrieval 테스트를 준비하던 중 문제 하나를 더 발견했다.
총 15,882개의 청크 중 **59개가 중복된 chunk_id**를 가지고 있었다.
예시:
e342ecd0f785c575dd25125e98bbd8e0f5e0d176::step:빚기 359b640d9be5fda55b426175eb84c293ff537805::step:숙성 1df327783d68fb73decfd1113aabe36e9ab7b6be::step:빚기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
대부분 `step:숙성`, `step:빚기`, `step:담금` 단계에서 겹쳤다.
확인해보니 하나의 레시피에 동일한 단계들이 들어가 있는 경우가 있었다.
---
## 5. Cleanup 스크립트
이 문제를 해결하기 위해 `sool_cleanup.py`를 작성했다.
- 단계 이름을 표준화 (`빚기 → 담금`, `거르기 → 여과`)
- 텍스트 뒤에 경량 메타데이터(KV) 추가
- 중복 청크 제거 (global / per-type 옵션 지원)
- 너무 긴 텍스트는 window/stride 방식으로 분할
```python
SECTION_SYNONYM = {
"빚기": "담금",
"담그기": "담금",
"덧술": "숙성",
"완성": "거르기",
"거름": "여과",
"거르기": "여과",
"정제": "여과",
}
def normalize_step_section(section: str) -> str:
raw = section.split(":", 1)[1].strip()
std = SECTION_SYNONYM.get(raw, raw)
return f"step:{std}"
결과적으로 고유 chunk_id 문제가 해결되었고, Retrieval 단계에서 중복으로 인한 잡음도 줄일 수 있었다.
6. 정리
sool_preprocess.py→ 정규화 + 영문 라벨 추가 + 파생치 생성sool_cleanup.py→ chunk 중복 제거 + 단계명 표준화 + 텍스트 분할- Kaggle에 공개하여 다른 학생 & 개발자들이 연구/교육용 데이터셋으로 활용 가능
전체 전처리 로직은 GitHub repo에 정리해 두었다.
전처리를 마치니 데이터셋이 훨씬 보기 좋아진 것 같다.
다음 편에서는 본격적으로 리트리버 파이프라인을 설계하는 과정을 다뤄 보겠다.