[AI 말평 대회] 참여기 #12: 3주차(4) - GRPO 학습 결과와 제출 성적 공유
[AI 말평 대회] 참여기 #12: 3주차(4) - GRPO 학습 결과와 제출 성적 공유
12. GRPO 학습 결과와 제출 성적 공유
#11까지는 구현과 메모리 관리였다면, 이번 편은 실제로 GRPO 학습을 통해 얻은 결과와 대회 서버 제출 성적을 공유한다.
1) WandB 학습 곡선
아래는 학습 중 WandB에서 기록한 지표들이다.
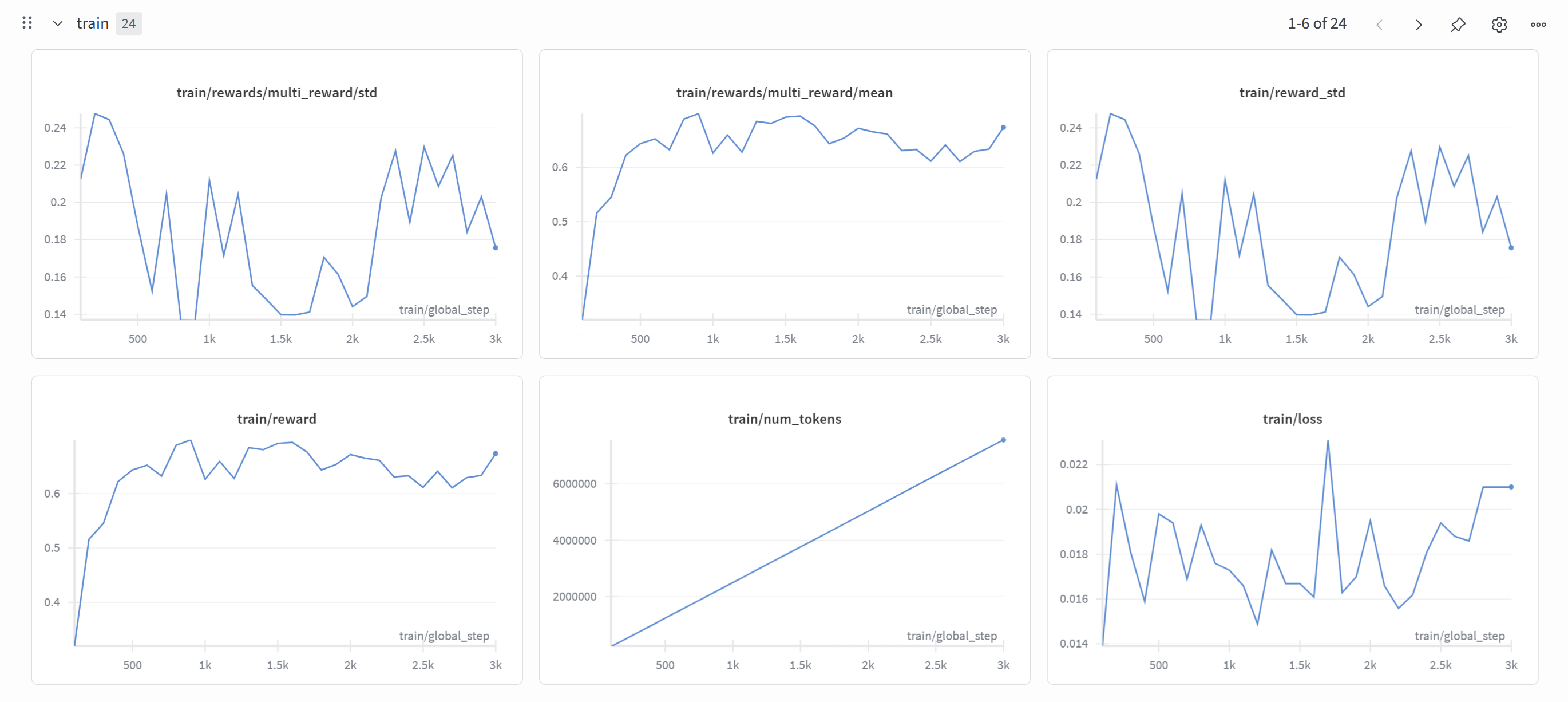
- multi_reward/mean: 초반 0.35 → 0.7 부근까지 상승 후 안정화
- reward: 평균적으로 0.6~0.7대 유지 → 학습이 안정적으로 진행됨을 의미
- loss: 대체로 0.015~0.02 사이에서 수렴
- std 지표들: 보상 편차가 줄어드는 구간이 존재 → 응답 일관성 개선 신호
2) Callback 평가 로그
학습 시 매 epoch 종료마다 InferenceCallback으로 검증셋 추론을 수행하고, evaluate_json.py로 점수를 계산했다.
| Epoch | ROUGE-1 | BERTScore | EM | Final Mean |
|---|---|---|---|---|
| 1 | 0.2730 | 0.6782 | 0.5197 | 0.4977 |
| 2 | 0.2962 | 0.6756 | 0.5197 | 0.5028 |
| 3 | 0.2677 | 0.6673 | 0.5433 | 0.5054 |
| 4 | 0.2979 | 0.6696 | 0.5984 | 0.5411 |
| 5 | 0.2917 | 0.6679 | 0.5591 | 0.5194 |
결론적으로 Best checkpoint는 Epoch 4 (Final Mean ≈ 0.54)인 것을 확인 가능했다.
3) 제출 결과 (대회 서버)
최종적으로 Epoch 4의 가중치를 제출했으며, 대회 서버에서 아래와 같은 성적을 기록했다.
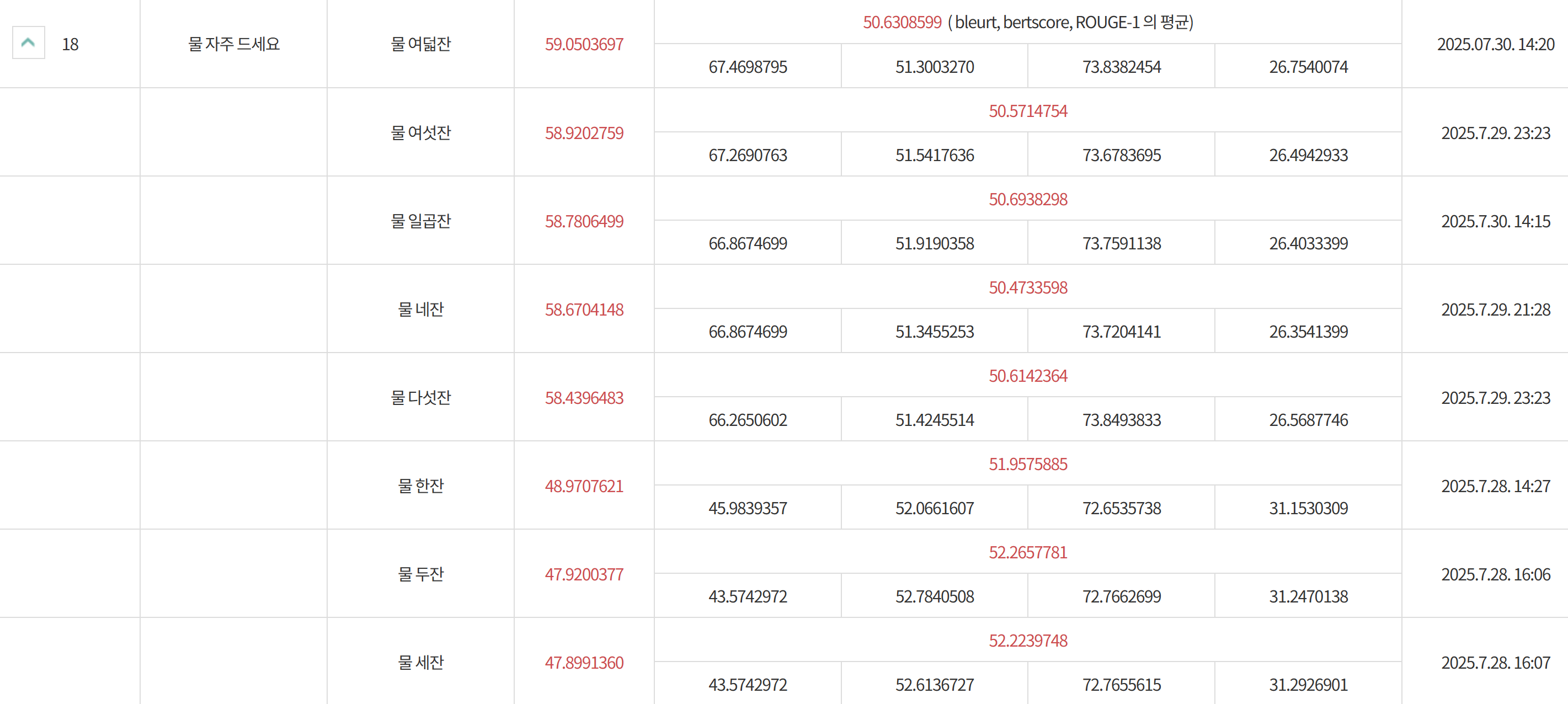
- 최종 점수 (BLEURT, BERTScore, ROUGE-1 평균): 50.63
- 세부 항목:
- BLEURT: 59.05
- BERTScore: 67.47
- ROUGE-1: 51.30
4) 분석 및 소감
- GRPO 학습을 통해 정답 문장 형식(“…이/가 옳다.”) 준수율과 EM이 확실히 개선되었다.
- 하지만 BLEURT, BERTScore는 여전히 중간 수준 → 이는 이유(reason) 문장의 품질이 제한적임을 의미.
- 여기서 얻은 인사이트: reason 부분을 단순 생성에 맡기지 않고, retrieval context와 결합하면 더 높은 품질을 기대할 수 있다.
- 즉, RAG와 RL을 접목하면 정답 포맷 + 이유 타당성을 동시에 강화할 수 있는 여지가 있다.
5) 마무리
이번 편에서는 WandB 로그, Callback 평가, 서버 제출 결과까지 전체 흐름을 정리했다.
이제 대회 기간이 얼마 남지 않아 다음번에는 대회 예선 후기로 돌아올 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.