[AI 말평 대회] 참여기 #3: 1주차(3) - 리더보드 분석과 후보 모델 탐색
[AI 말평 대회] 참여기 #3: 1주차(3) - 리더보드 분석과 후보 모델 탐색
AI 말평 대회 참여기 #3: 1주차(3) - 리더보드 분석과 후보 모델 탐색
이전 글에서는 평가 지표를 정리했다면,
이번 글에서는 Horangi LLM 리더보드와 벤치마크를 분석하고
가장 좋은 모델을 찾기 위한 Baseline 후보 모델 탐색을 진행한 과정을 정리한다.
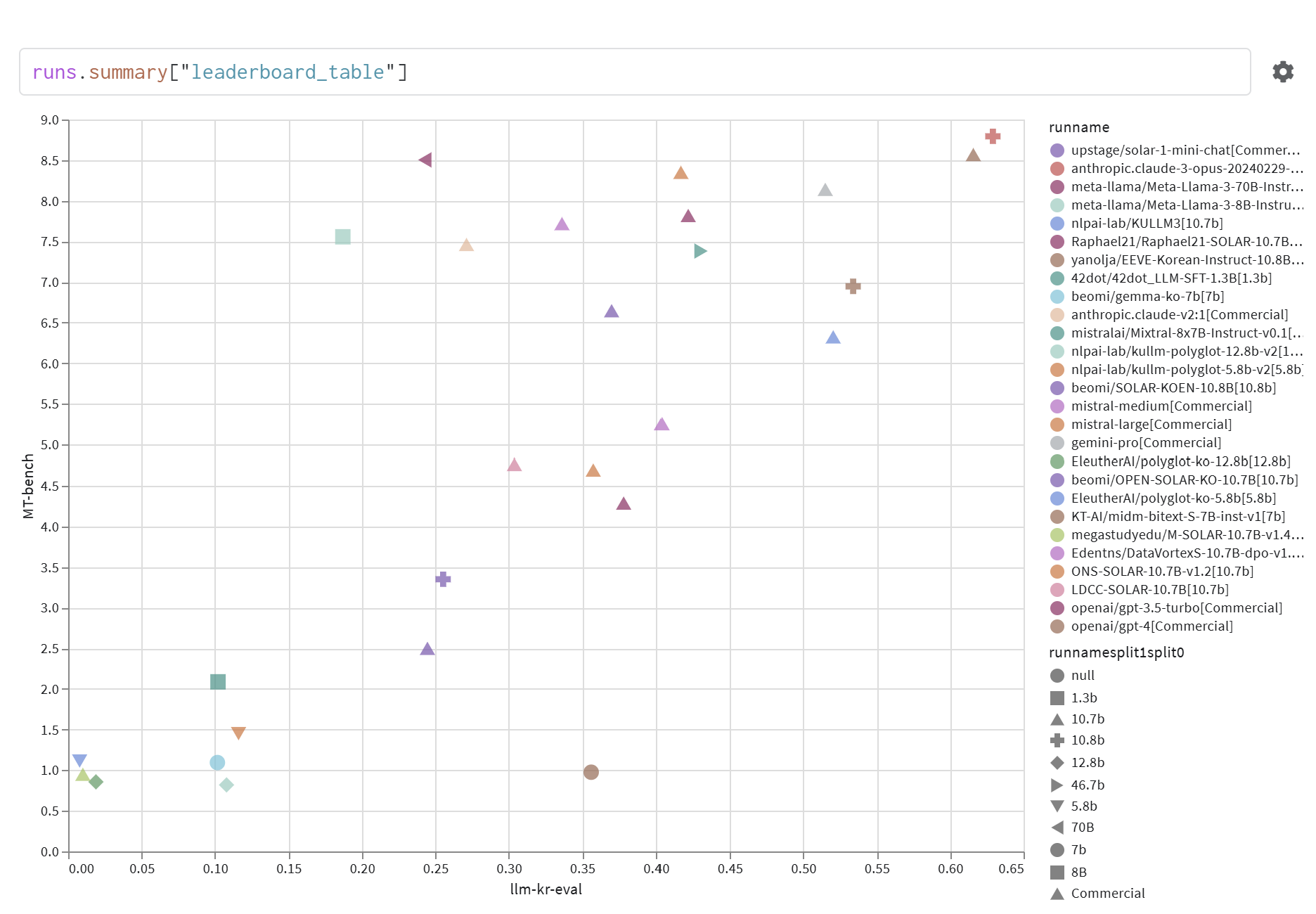
모델 탐색 이전에 팀원분이 호랑이 Horangi LLM 리더보드와 벤치마크 점수가 높은 모델 위주로 찾아보라고 조언 해주셨다. 그래서 두 평가 요소를 가지고 모델을 탐색 해보았는데 오늘은 그 과정에서 알게 된 것들을 정리해본다.
1. Horangi LLM 리더보드 (간결 설명)
호랑이 LLM 리더보드는 거대언어모델(LLM)의 한국어 능력을 평가하기 위한 도구로,
다음 두 가지 방식으로 종합적인 평가를 수행한다.
- 언어 이해 (NLU) – llm-kr-eval
- 일본어
llm-jp-eval기반 → 한국어 버전 개발 - Q&A 형식의 자연어 이해 평가
- 일본어
- 언어 생성 (NLG) – MT-Bench
- Multi-turn 대화를 통한 생성 능력 평가
리더보드는 Weight & Biases(W&B)의 테이블 기능을 활용해
- 모델별 점수 비교
- 실험 기록 추적
을 손쉽게 수행할 수 있도록 설계되었다.
핵심 점수: llm-kr-eval 점수 + MT-Bench 점수
2. 벤치마크 상세 설명
2-1. llm-kr-eval
- 개요: 일본어
llm-jp-eval을 한국어용으로 수정 - 목적: 한국어 LLM의 NLU 능력 측정, 생성 기반 평가
태스크별 설명
- NLI (Natural Language Inference)
- 두 문장의 논리적 관계를 판별 (entailment/neutral/contradiction)
- 데이터셋: KorNLI, KoBEST HellaSwag, KoBEST COPA
- 모델의 논리 추론 및 문장 관계 이해 능력 측정
- QA (Question Answering)
- 질문에 대한 정확한 단답형/지식 기반 응답 평가
- 데이터셋: KoBEST WiC, KMMLU
- 모델의 질문 이해 및 정답 생성 능력 평가
- RC (Reading Comprehension)
- 문맥 독해 및 문장 유사도 평가 (예: KorSTS)
- 데이터셋: KorSTS, KoBEST SN
- 모델의 독해력·문장 의미 파악 능력 측정
- EL (Entity Linking)
- 문장에서 개체명 식별 및 관계 추출 수행
- 데이터셋: KLUE-NER, KLUE-RE
- 모델의 개체 처리 및 관계 이해 능력 평가
- FA (Fundamental Analysis)
- 주어진 단어 조합으로 자연스러운 문장 생성
- 데이터셋: Korean-CommonGen
- 모델의 창의적 문장 생성 능력 평가
태스크 및 데이터셋
| Task | Dataset | Metric | 링크 |
|---|---|---|---|
| NLI | KorNLI, KoBEST HellaSwag, KoBEST COPA | exact | KorNLI, kobest |
| QA | KoBEST WiC, KMMLU | exact | kobest, KMMLU |
| RC | KorSTS, KoBEST SN | pearson/spearman, exact | KorSTS, kobest |
| EL | KLUE-NER, KLUE-RE | set_f1, exact | klue |
| FA | Korean-CommonGen | BLEU | Korean-CommonGen |
- 평가 방식
- exact → Exact Match
- char_f1 → 문자 단위 F1
- set_f1 → 집합 단위 F1
- 생성 기반 평가를 위해 기존 데이터를 instruction 포맷으로 변환
2-2. MT-Bench
- 개요:
llm-sys개발 멀티턴 QA 벤치마크 (한국어 버전은 Horangi 프로젝트 번역) - 목적: LLM의 대화형 생성 능력(NLG) 평가
- 구성
- 총 80문항, 8개 카테고리
- Writing
- Roleplay
- Extraction
- Reasoning
- Math
- Coding
- Knowledge I (STEM)
- Knowledge II (인문/사회)
- 총 80문항, 8개 카테고리
- 특징
- 멀티턴 대화 속 명령 수행 능력 측정
- 답변이 유일하지 않음 → GPT-4 기반 정성적 평가
- 링크
2-3. 추가 한국어 벤치마크
이 벤치마크들을 종합적으로 참고해 후보 모델을 탐색했다.
3. 후보 모델 탐색
한국어 문법 교정 Task를 수행해야 하므로
한국어 능력이 높은 모델을 우선적으로 선정했다.
참고 지표: Horangi Leaderboard / HAERAE / KoBEST / KMMLU / LogicKor
- trillionlabs/Trillion-7B-preview
- HAERAE: 80.2, KoBEST: 79.61
- 한국어 BenchMark 점수 높음
- dnotitia/Llama-DNA-1.0-8B-Instruct
- KMMLU: 53.3, KoBEST: 83.4
- 한국어 BenchMark 점수 우수
- NCSOFT/Llama-VARCO-8B-Instruct
- LogicKor: 8.82 (Grammar: 8.57)
- 문법 관련 성능 확인
- saltware/sapie-gemma2-9B-it
- 리더보드 상위권
- AVG_llm_kr_eval: 0.6309 / AVG_mtbench: 7.325
- KRAFTON/KORani-v3-13B
- 한국어 QA 특화
- RAG나 교정형 Task에 적용 가능성 있음
4. 다음 계획
- 위 후보 모델로 Baseline 추론 실행
- 평가 지표(EM + BLEURT + BERTScore + ROUGE)를 활용해 성능 확인
- 이후 성능 비교 및 최종 후보 모델 선정
다음 글에서는 Baseline 추론을 다룰 예정이다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.