[AI 말평 대회] 참여기 #5: 1주차(5) - 프롬프트 설계, CoT, 모델 성능 비교

[AI 말평 대회] 참여기 #5: 1주차(5) - 프롬프트 설계, CoT, 모델 성능 비교
AI 말평 대회 참여기 #5: 1주차(5) - 프롬프트 설계, CoT, 모델 성능 비교
이번 글에서는 본격적인 추론을 위한 프롬프트 설계에 대해 공부해본 내용을 정리해본다.
1. 프롬프트 개념과 프롬프트 엔지니어링
1-1. 프롬프트란?
- LLM에 입력되는 명령어 또는 지시문
- 모델은 프롬프트를 기반으로 다음 토큰을 예측해 답변을 생성
- 예시:
1
"다음 문장에서 틀린 부분을 교정하시오: 감기가 빨리 낳았으면 좋겠다."
- 프롬프트 품질이 곧 출력 품질과 직결
→ 형식 유지, 답변 정확도, reasoning 안정성까지 모두 영향을 준다.
1-2. 프롬프트 엔지니어링이란?
- 원하는 출력을 얻기 위해 프롬프트를 설계·최적화하는 과정
- 목적:
- 모델 출력 안정화
- 포맷 준수 강제
- 사고 과정(reasoning) 유도
- 주요 기법:
- 출력 형식 강제 →
"정답 문장"가 옳다형식 - 질문 반복 금지
- 외부 규범/지식 주입 (RAG-enhanced Prompting)
- 출력 형식 강제 →
1-3. 주요 하위 기법
(1) Few-shot Prompting
- 정의: 모델에 예시를 1~5개 제공해 패턴을 학습하게 함
- 장점:
- 소량 예시만으로도 성능 향상 (특히 EM↑)
- Zero-shot 대비 오류 감소
- 단점:
- 토큰 소모 증가
- 예시 선택이 성능에 직접 영향
(2) Chain-of-Thought (CoT)
- 정의: 답을 바로 내지 않고 사고 과정을 단계적으로 유도
- 장점:
- 복잡한 문법/추론 문제에서 정확도 상승
- Self-Verification 효과 (자가 검증)
- 단점:
- reasoning이 그대로 출력되면 포맷 깨짐 발생
- 추론 단계가 길어지면 속도 저하 가능
2. 프롬프트 설계 과정과 이슈
모델 추론을 돌려보면서 반복적으로 몇가지 문제들이 나타났다. 일단 프롬프트를 개선해서 이러한 문제들을 해결해보려고 했는데 이를 정리하면 다음과 같다.
- 경어체 출력 문제
- ”
~습니다” 같은 경어체 출력 - 해결:
1
답변은 경어체가 아닌 “"{선택·교정 문장}"가/이 옳다. {이유}” 형식을 무조건 지키시오
- ”
- 질문 반복 출력 문제
- 답변 앞에 질문을 그대로 복붙
- 해결:
1
답변 이전에 질문을 그대로 출력하지 마시오
- 두 문장 모두 옳다고 판단
- 선택형 문제에서 두 문장을 동시에 정답 처리
- 해결:
1
두 문장 중 한 문장은 문법적으로 틀렸다
- Test set에 정답이 없어 Retrieval 어려움 (이후의 과정에 대한 문제)
- 해결책: Category → Rule Prompting
- 틀린 단어 판단
- 관련 규범(Category) 추론
- 규범 근거(Rule)로 교정
- 해결책: Category → Rule Prompting
3. 모델별 추론 성능 비교
추론을 돌려본 모델중 일부 모델을 채점한 결과는 다음과 같았다. Trillion-7B 모델에 대해 3-shot Prompting을 적용하자 점수가 크게 오르는 것을 확인 가능했다.
다른 팀원분들이 추론을 돌려본 결과 카카오의 Kanana-8B가 성능이 괜찮게 나와서 일단 베이스 모델로 Kanana-8B를 사용하고 이후 더 좋은 모델이 발견되면 교체하기로 하였다.
(점수 순서: Final / EM / BLEURT / BERTScore / ROUGE-1)
| 모델 | 프롬프트 | Final | EM | BLEURT | BERTScore | ROUGE-1 |
|---|---|---|---|---|---|---|
| Trillion-7B | 기본 | 45.77 | 41.77 | 49.55 | 71.50 | 28.27 |
| Trillion-7B | 3-shot | 49.98 | 50.40 | 48.53 | 71.99 | 28.14 |
| Llama-DNA-8B | 기본 | 41.08 | 33.33 | 49.79 | 70.38 | 26.31 |
| Kanana-8B | 기본 | 48.38 | 45.78 | 52.85 | 71.20 | 28.86 |
| Llama-VARCO-8B | 기본 | 41.85 | 35.94 | 51.19 | 69.09 | 22.96 |
| Llama-3 Open-Ko-8B | 기본 | 23.67 | 0.00 | 52.59 | 68.04 | 21.38 |
4. 모델별 성능 시각화
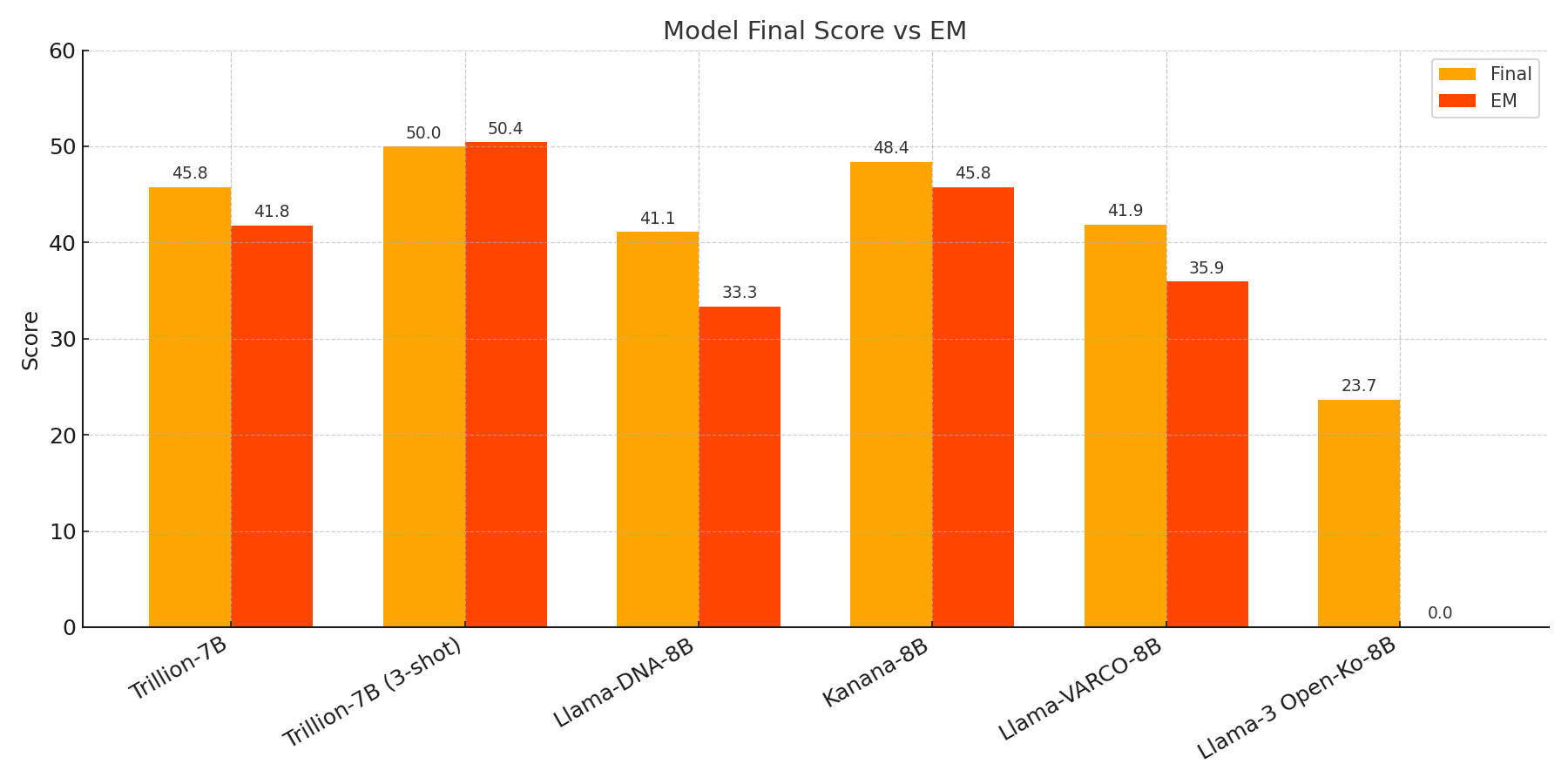
- Final과 EM 중심 비교
- BLEURT/BERTScore는 문장 품질, ROUGE-1은 표면 유사도 확인용
5. 배운 점 & 다음 계획
이번 과정을 통해 프롬프트의 개선이 상당한 성능 향상을 불러온다는걸 직접 눈으로 확인할 수 있었다.
다음 시간에는 본격적인 학습 이전에 RAG에 대해 공부한 내용을 공유하고자 한다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.