[AI 말평 대회] 참여기 #6: 2주차(1) - RAG 구조 & OMNI RAG & RAGChecker
AI 말평 대회 참여기 #6: 2주차(1) - RAG 구조 & OMNI RAG & RAGChecker
본격적인 모델 학습 과정을 시작하기 이전에 RAG에 대한 개념을 확실히 잡고 가면 좋겠다는 생각이 들어서 RAG에 대한 학습을 진행하였다. 학습 자료는 가천대학교 신기술특론 강의에서 셀렉트스타 이정수 선임연구원님과 KT의 허윤석 선임연구원님이 강의하신 내용을 많이 참고하였다.
그럼 2주차의 시작은 RAG(Retrieval-Augmented Generation) 구조와
OMNI RAG, 그리고 RAGChecker 기반 평가를 정리하면서 시작하겠다.
이번 글에서는 RAG 개념 → 고급 구조 → OMNI RAG → RAG 평가 → 청킹 예시 → References 순으로 정리한다.
1. RAG 개념
- 정의: LLM이 외부 지식을 직접 학습하지 않고, 필요한 정보를 검색 후 생성
- 핵심 아이디어
1
Query → Retriever → (Top-k Documents) → Generator → Answer
- 장점
- 최신 정보 활용 가능
- 모델 파라미터 수 최소화
- Hallucination 감소
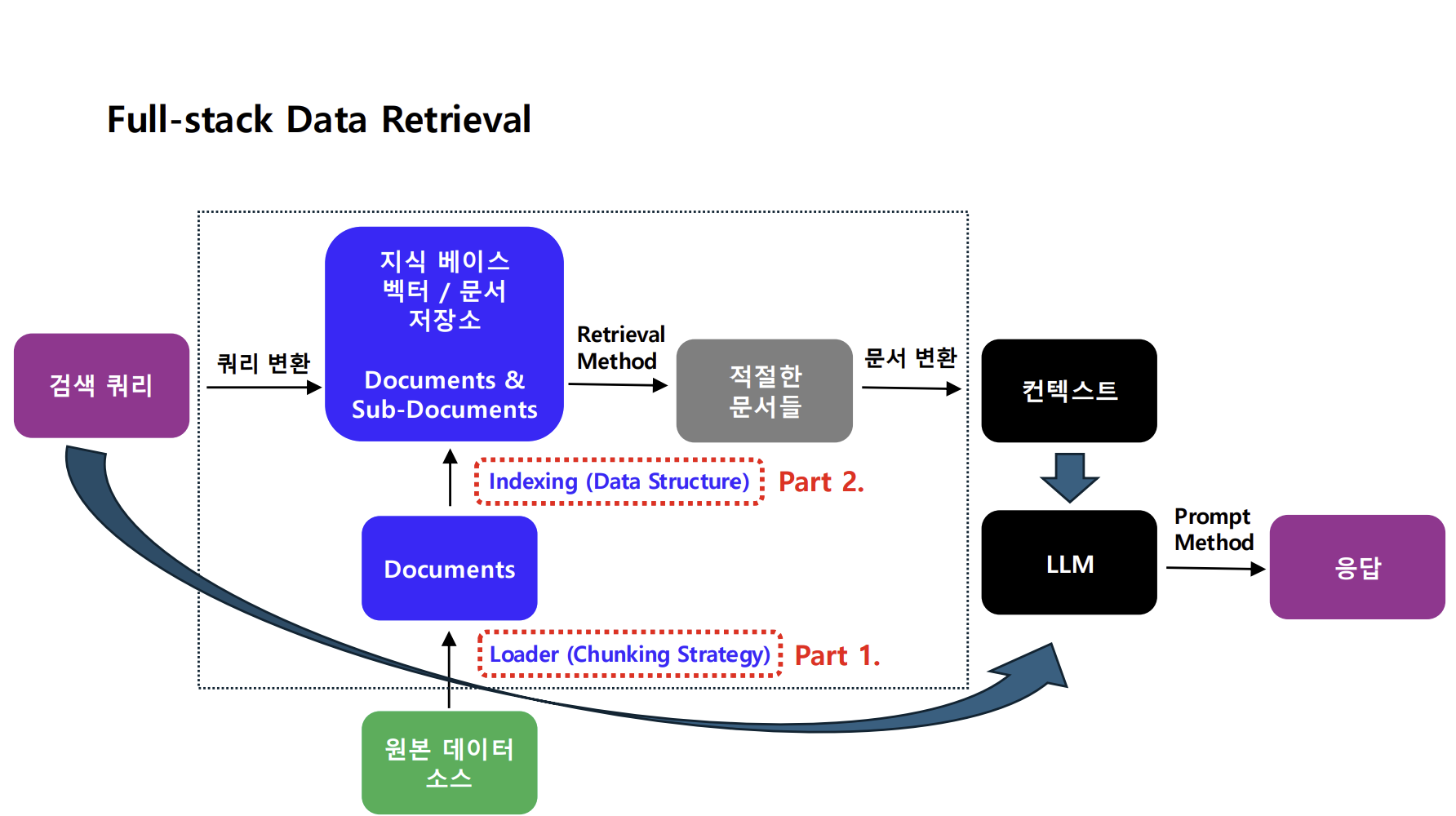 기본 RAG 구조
기본 RAG 구조
2. Chunking & Indexing
2-1. Chunking
- 문서를 적절히 쪼개어 LLM에 효율적으로 제공
- 레벨별 전략
- Fixed-size Chunking (단순 고정 길이)
- Recursive Chunking (Separator 기반 구조 유지)
- Document-based (Markdown, Code, Table 기반)
- Semantic Chunking (유사도 기반 문장 그룹화)
- Agentic Chunking (LLM이 청킹 직접 수행)
Tip: 의미 기반 청킹(Level 4~5)은 RAG 성능 향상에 크게 기여
청킹 예시 (Chunking Example)
| Chunking 유형 | 예시 |
|---|---|
| Fixed-size | 문장을 300토큰 단위로 단순 분할 |
| Recursive | Heading/Section 기준으로 계층적 분할 |
| Semantic | 의미 유사도가 높은 문장끼리 그룹화 |
| Agentic | LLM이 스스로 의미 단위 청킹 수행 |
 Chunking 전략 예시1
Chunking 전략 예시1
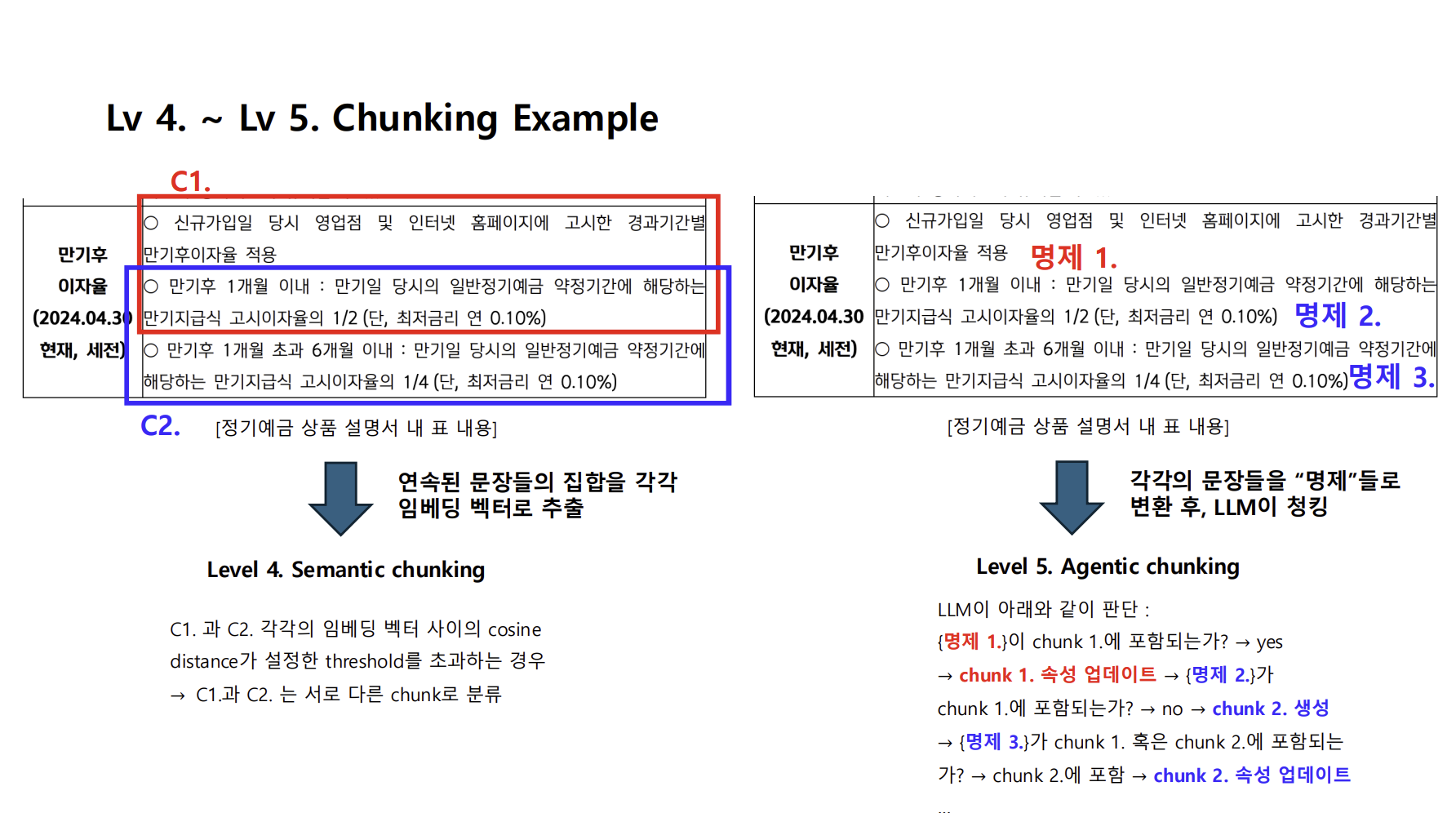 Chunking 전략 예시2
Chunking 전략 예시2
흥미롭게도 Dense X Retrieval: What Retrieval Granularity Should We Use? (2024 EMNLP)에 따르면 명제로 Chunking을 진행하면 QA 퍼포먼스가 향상한다고 한다.
명제(Proposition)는 독립적으로 존재하고 독립적으로 존재하면서 “self-explanatory”한 문장이다. 때문에 명제는 다음과 같은 특징을 가진다.
- 명제는 “간결”하고 “Self-contained”하다.
- 명제는 “일반화”가 가능하다. (모델이 학습하지 않은 데이터셋에도 효과적)
- 명제로 청킹할 경우, 적합한 정보의 밀도가 더 높다.
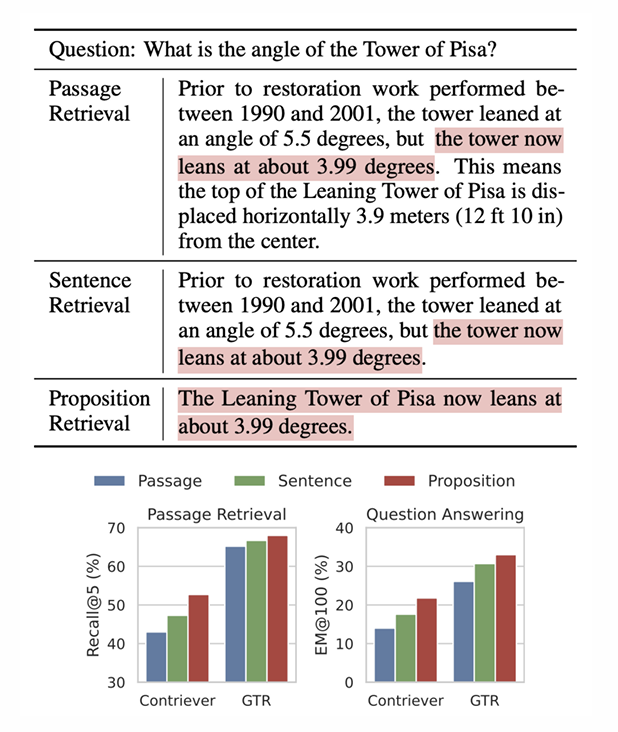 Proposition Chunking 전략
Proposition Chunking 전략
우리가 대회에서 진행하는 작업이 QA인 만큼 이 내용을 어딘가 활용할 곳이 있을거라는 생각이 들었다.
2-2. Indexing
- Chunk를 검색 가능하게 만드는 단계
- 주요 전략
- Multi-vector Indexing (요약, 예상 질문, child doc)
- Tree-based Indexing (RAPTOR 구조, 다층 요약)
- Graph-based Indexing (GraphRAG, 지식 그래프 기반)
 RAPTOR(TreeRAG) 구조
RAPTOR(TreeRAG) 구조
3. Retriever & Reranker
- Retriever
- Dense: DPR(Dense Passage Retrieval), Sentence-BERT, Contriever
- Sparse: BM25, ElasticSearch
- Hybrid: Dense + Sparse
- Reranker
- Cross-Encoder 기반 정밀 재정렬
- Multi-Stage Retrieval과 함께 사용 시 성능↑
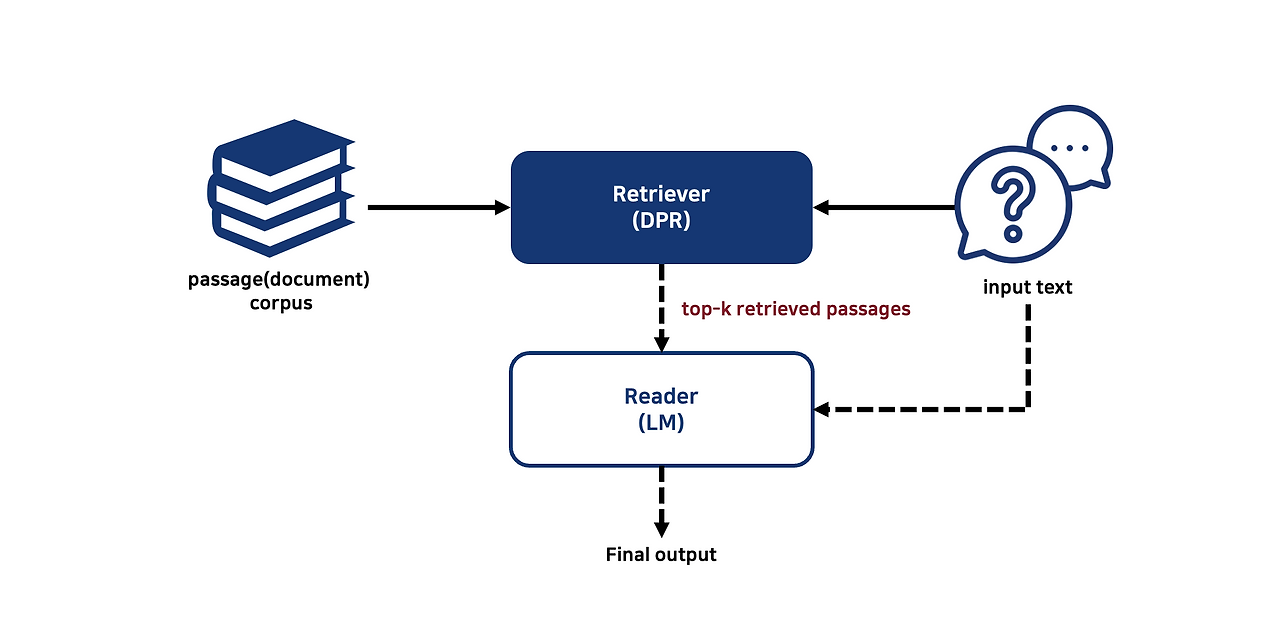 DPR(Dense Passage Retrieval) 구조
DPR(Dense Passage Retrieval) 구조
4. Query 유형
- Single-hop Query
- 단일 문서 기반
- ex) “아인슈타인이 상대성 이론을 발표한 해는?”
- Multi-hop Query
- 복합 추론 필요, 다중 문서 참조
- ex) “상대성 이론에 영향을 준 과학자와 그들의 이론은?”
- 구체적 vs 추상적 쿼리
- 구체적: Fact 중심
- 추상적: 해석·설명 요구 → GraphRAG 적합
5. 고급 RAG 구조
5-1. Multi-Stage RAG
1
2
3
Query → Dense Retriever → Top-k
→ Cross-Encoder Reranker → Top-n
→ Generator
5-2. TreeRAG (RAPTOR)
- 문서를 Tree 구조로 요약
- 상위→하위 노드 다층적 Context 활용
- NarrativeQA 등 멀티홉 QA 성능 향상
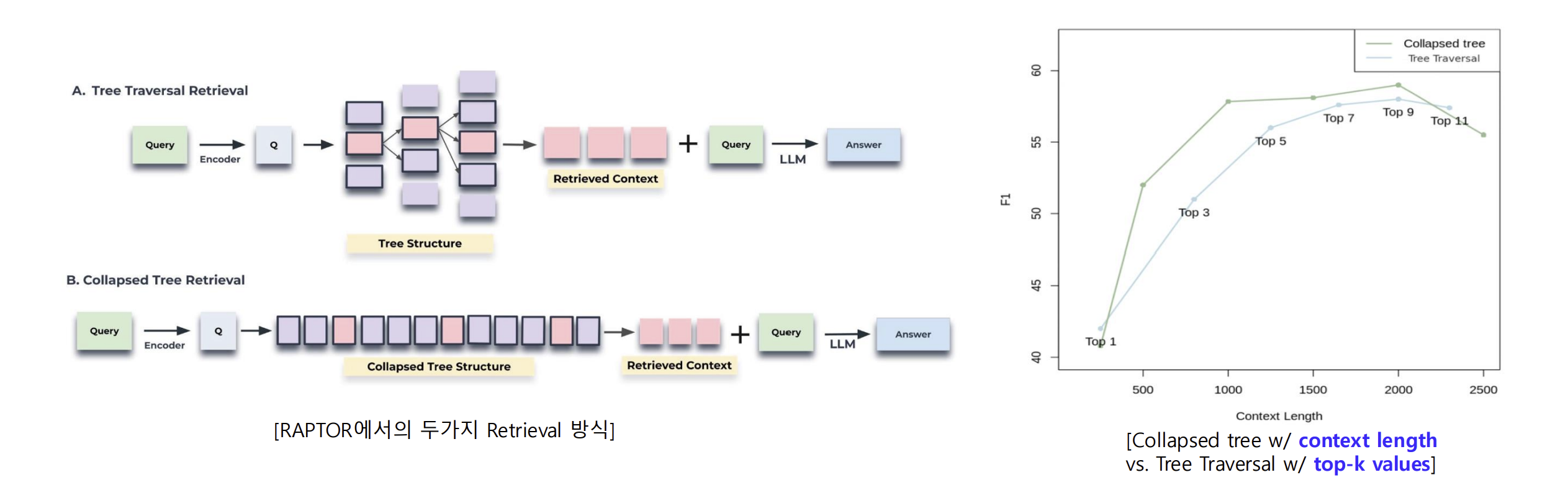
- Tree Traversal, Collapsed Tree 두가지 Retrieval 방식으로 나뉨
- Tree Traversal : 쿼리의 시멘틱 벡터와의 유사도 비교로 Tree Traversal (Top-k values)
- Collapsed Tree : 트리를 전부 펼쳐놓고 일일이 유사도 비교 (Fixed Context Length)
- RAPTOR Tree로 정보를 구조화한 후, Collapsed Tree Retrieval하는 방식이 더 좋음.
5-3. GraphRAG
- 문서를 지식 그래프로 변환
- Local Search + Global Search
- 추상적·멀티홉 질문 대응력 강화
5-4. OMNI RAG
팀원분이 OMNI RAG에 대한 논문(Leveraging LLM-Assisted Query Understanding for Live Retrieval-Augmented Generation)을 공유해주셔서 OMNI RAG에 대해서도 학습을 진행했다.
아래에 직접 작성한 논문 요약 노트를 공유한다.
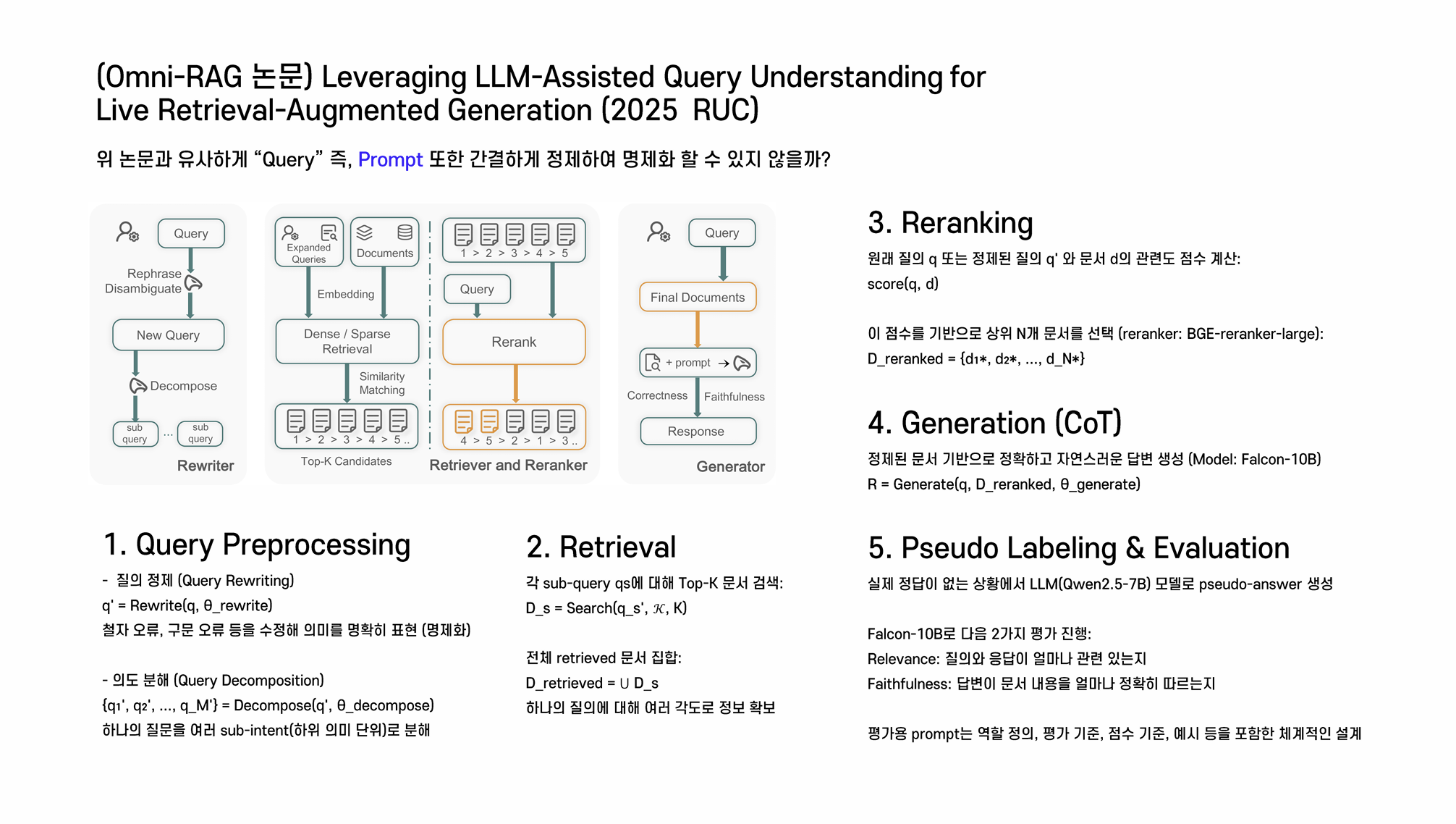 OMNI RAG 스터디 노트
OMNI RAG 스터디 노트
- 개념
- 기존 RAG 한계를 극복하기 위해 여러 Retrieval 모듈을 통합
- 단순 Top-k 검색이 아닌 문서·테이블·멀티모달 소스 활용
- 구성
- Omni Retriever
- 텍스트 + 표 + 이미지 기반 검색
- Agentic Chunking과 결합 가능
- Omni Reasoner
- 검색 결과를 통합 reasoning
- CoT + Self-Verification 연계
- Omni Generator
- 다양한 소스 기반 최종 답변 생성
- Omni Retriever
- 장점
- 단일 RAG 대비 검색 누락 최소화
- 멀티모달 RAG 가능
- Multi-hop·Abstract Query 대응력↑
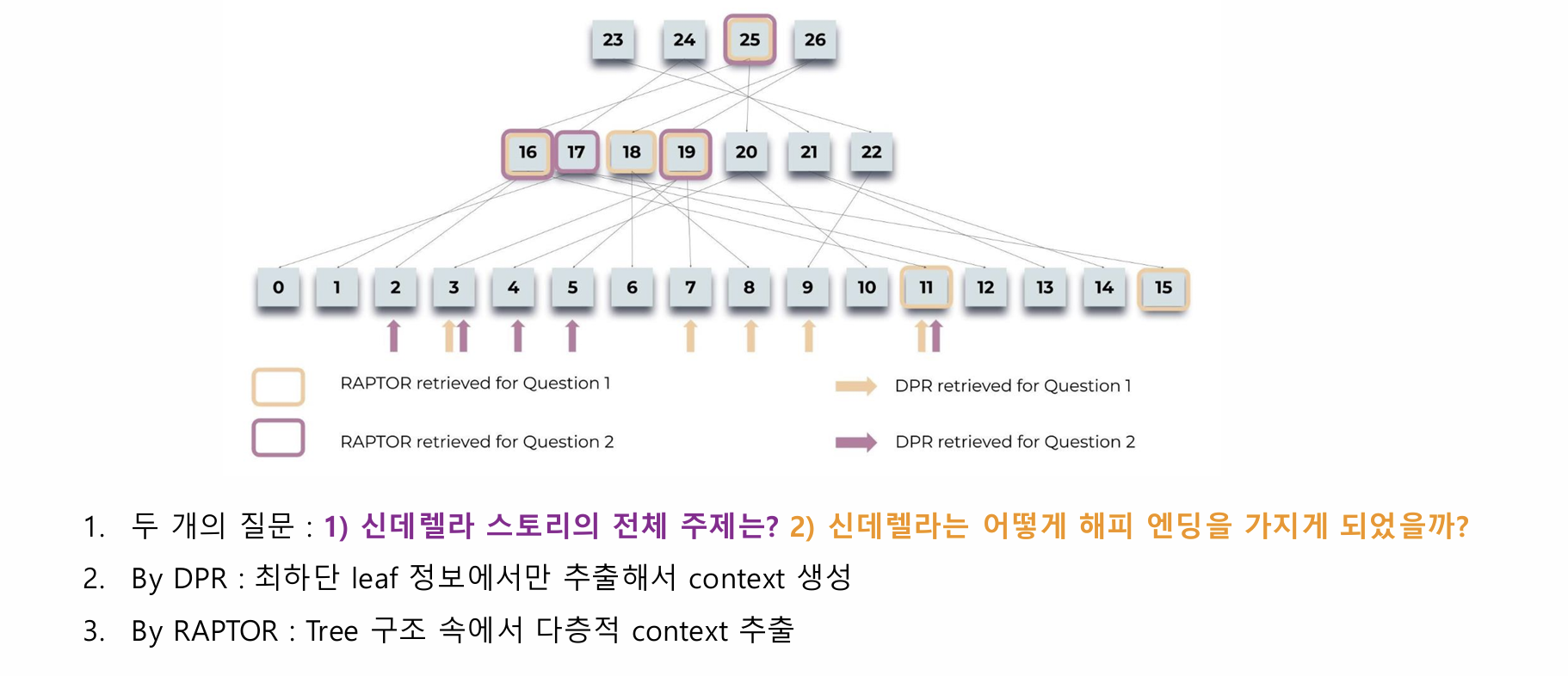 RAPTOR vs. DPR
RAPTOR vs. DPR
공부를 하던 도중 흥미로운 내용을 추가로 발견했다. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval에 따르면 RAPTOR가 다양한 QA task들에서 DPR(Dense Passage Retrieval)보다 성능이 더 좋다고 한다. DPR은 최하단 leaf 정보에서만 추출해서 context를 가져오지만 RAPTOR는 Tree 구조 속에서 다층적인 context를 추출하기 때문이다.
그리고 GRAPH RAG에 대해서 LLM을 지식그래프를 만드는데 사용 가능하다는 것도 알게 되었다. From Local to Global: A Graph RAG Approach to Query-Focused Summarization라는 논문에서는 다음과 같은 과정을 거쳐 답변을 생성한다.
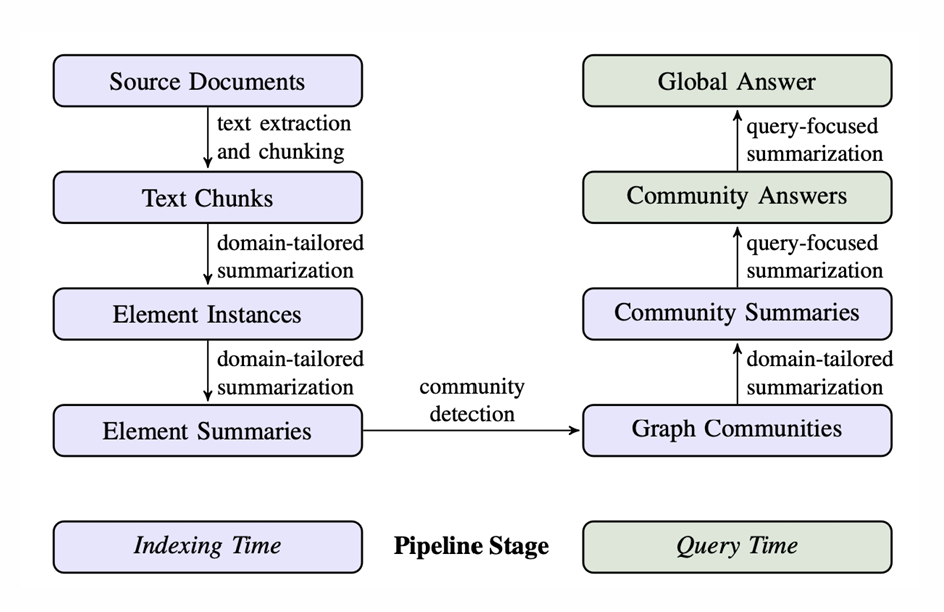 GRAPH RAG with LLM
GRAPH RAG with LLM
- LLM을 활용하여 전체 text에서 (entities, connections, covariates)를 추출하여 지식 그래프 생성
- 그래프 알고리즘(ex. Leiden)을 활용하여 Community detection
- 각 계층별 community summaries를 활용하여 답변 생성(map-reduced approach)
GraphRAG는 데이터셋에 대한 전체론적인 이해가 가능하고 전용 쿼리를 사용하면 세부 정보 및 전체론적 의미 를 함께 고려한 검색이 가능하기 때문에 이러한 GRAPH RAG를 대회에 활용해볼수는 없을까? 라는 생각을 해봤다.
대회 기간이 길지 않아 논문들의 내용을 간단하게 보고 넘어갔기 때문에 이러한 내용을 이후에 좀 더 자세하게 따로 정리해보는 것도 좋을것 같다는 생각이 들었다.
6. RAG 평가 방법 & RAGChecker
기존 평가 지표
- 정답 기반 평가
- EM (Exact Match), ROUGE, BLEURT, BERTScore
- RAG 특화 평가
- Precision / Recall / F1
- Hallucination Rate
- Coverage (Retrieved vs Needed)
RAGChecker
- Amazon AWS AI 팀이 제안한 RAG 전용 평가 프레임워크
- Ret rieval & Generation을 모듈 단위로 평가
- Claim-level entailment 기반으로 세밀한 품질 측정
평가 흐름
1
2
3
4
5
6
7
8
9
10
Query + Ground Truth
│
▼
Retriever → Top-k Docs
│
▼
Generator → Response
│
▼
Claim 추출 및 정합성 검사 → RAGChecker Metrics
핵심 지표
- Retriever Metrics
- Claim Recall: 정답에 필요한 claim을 얼마나 검색했는가
- Context Precision: 검색 문서 중 유효 문서 비율
- Generator Metrics
- Faithfulness: Retrieval에 충실한가
- Noise Sensitivity: 불필요 정보 민감도
- Hallucination Rate: 검색 문서에 없는 내용 생성 비율
- Context Utilization: Retrieval 활용도
- 통합 점수
- Retrieval vs Generation 병목 파악 가능
- Human Evaluation과 높은 상관관계
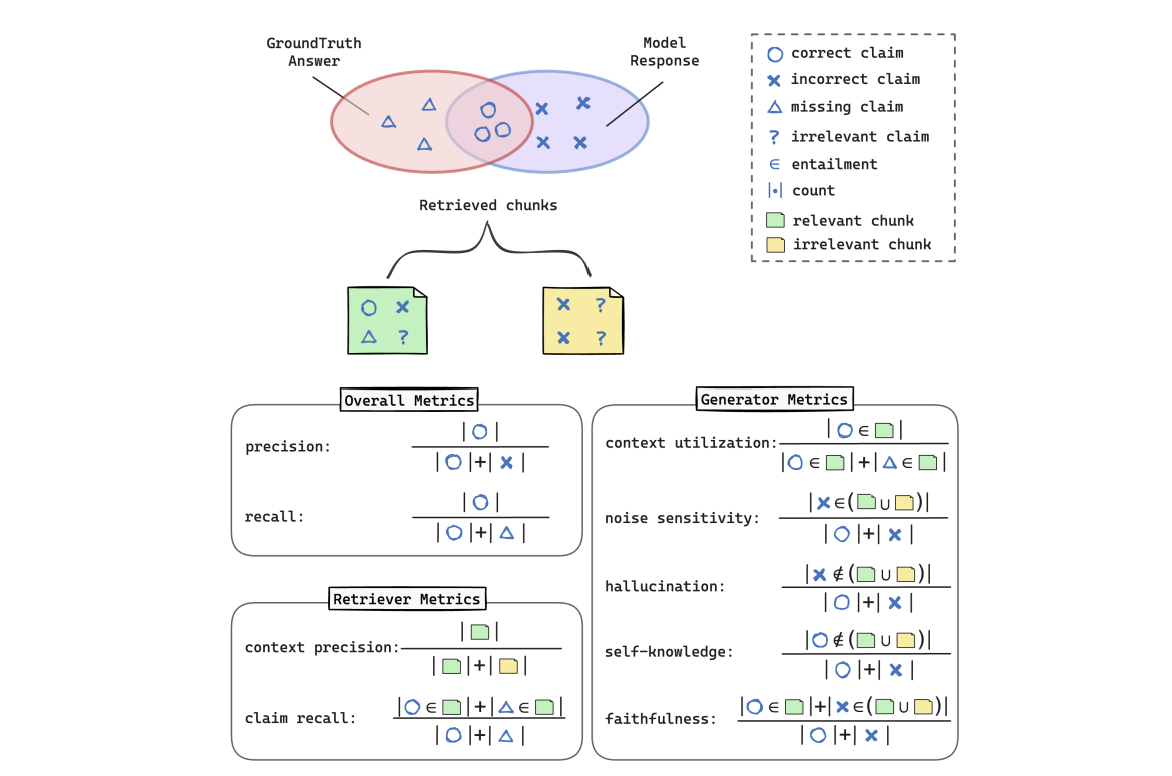 RAGChecker 평가 수식
RAGChecker 평가 수식
Tip:
RAGChecker를 활용하면 단순 Output 평가가 아닌
검색→생성 전체 파이프라인의 병목을 진단할 수 있다.
7. 배운 점 & 느낀점
RAG 설계는 Chunking & Indexing 품질이 핵심이라는 생각이 들었다. 어찌되었건 Query에 맞는 Context를 가져와야 모델이 정확한 답변을 할 수 있기에 정확한 Context를 찾기 위한 많은 방법론들(OMNI RAG, GraphRAG, RAPTOR, DPR)이 탄생했다고 생각한다.
그리고 RAG를 평가할 때 실무에서는 어떤 식으로 평가가 진행될지 무척이나 궁금했는데 RAGChecker와 같은 RAG 시스템의 전체 파이프라인을 평가 가능한 도구가 있다는 것을 새롭게 배운것 같다.
이번 대회 정리에서는 간단하게 짚고 넘어갔지만 공부도중 RAPTOR, DPR에 대한 다양한 논문을 발견했는데 공부 후 정리해보기로 결심하였다.
References
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP, NeurIPS 2020.
- Darren Edge., Dense X Retrieval: What Retrieval Granularity Should We Use?, EMNLP 2024.
- Xiaoxi Li., Leveraging LLM-Assisted Query Understanding for Live Retrieval-Augmented Generation, 2025.
- Khattab et al., RAPTOR: Recursive Abstractive Processing for Tree-based Organization of Retrievals, EMNLP 2023.
- Vladimir Karpukhin., Dense Passage Retrieval for Open-Domain Question Answering, EMNLP 2020.
- Amazon AWS AI, RAGChecker: Fine-grained Evaluation of Retrieval-Augmented Generation, 2024.
- KT 허윤석 선임연구원, 셀렉트스타 이정수 선임연구원, 가천대학교 신기술특론 강의 자료, 2025.