[AI 말평 대회] 참여기 #8: 2주차(3) - 듀얼 인코더(간편 버전) 구현과 실험

AI 말평 대회 참여기 #8: 2주차(3) - 듀얼 인코더(간편 버전) 구현과 실험
지난 편(#7)에서 Retrieval 구조와 데이터셋, PPL 기반 후보 수집을 정리했다. 이번 편은 가장 빠르게 결과를 확인하기 위해, 파인튜닝 없이 Sentence-Transformers + HF Cross-Encoder로 구성한 간편 버전을 기록한다. 커스텀 듀얼 인코더 학습(MNR/CE Loss)은 다음 편에서 다룬다.
1) 실행 스크립트 (entrypoint)
간단한 CLI 인자와 함께 파이프라인을 실행한다.
1
2
3
4
5
6
7
8
9
10
# main.py (요약)
args = get_args()
pipe = RetrieverPipeline(
grammar_path=args.grammar,
qa_path=args.qa,
biencoder_name=args.biencoder_name, # SentenceTransformer bi-encoder
cross_name=args.cross_name, # HF cross-encoder
device=args.device
)
pipe.run(top_k=args.top_k, top_n=args.top_n, save_path=args.out)
--biencoder_name,--cross_name으로 모델을 바꿔가며 실험하기 쉽게 했다.- 기본값:
jhgan/ko-sroberta-multitask(bi) +snunlp/KR-SBERT-V40K-klueNLI-augSTS(cross).
2) 파이프라인 구성
2.1 Bi-Encoder로 초기 검색
- 전체 규범 문서(
GrammarBook_structured.json)의description을 미리 임베딩한다. - 질의는 실행 시 임베딩해 semantic_search로 상위
top_k후보를 뽑는다.
1
2
3
4
5
6
7
8
9
10
11
# RetrieverPipeline.py (요약)
self.biencoder = SentenceTransformer(biencoder_name, device=device)
# 컨텍스트 인덱스 구축
self.context_texts = [rule['description'] for rule in self.grammar_book]
self.context_embs = self.biencoder.encode(
self.context_texts, batch_size=256, convert_to_tensor=True, show_progress_bar=True
)
# 초기 검색
hits = util.semantic_search(question_emb, self.context_embs, top_k=top_k)[0]
2.2 Cross-Encoder로 재정렬
- (질문, 후보문맥) 쌍을 만들고 크로스인코더 점수로
top_n을 최종 재정렬한다.
1
2
3
4
5
6
# Cross-Encoder rerank (요약)
inputs = self.cross_tokenizer(pairs, padding=True, truncation=True, max_length=512, return_tensors="pt").to(device)
with torch.no_grad():
logits = self.cross_model(**inputs).logits
if logits.dim()==2 and logits.size(1)==2: logits = logits[:, 1] # positive logit
top_vals, top_idx = torch.topk(logits, k=min(top_n, len(candidates)))
2.3 결과 저장 & 간단 평가
- 각 질문에 대해 선택된 상위
top_n컨텍스트와 정답 규정(rule_id)이 포함되었는지를 기록. - 마지막에 Recall(top
n)을 출력.
1
2
3
4
5
# 저장 및 Recall 계산 (요약)
with open(save_path, "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
recall = sum(r['Gold_in_topN'] for r in results) / len(results)
print(f"Recall(top {top_n}): {recall:.2%}")
유틸 함수(파일 로드/경로 체크)는 재사용성을 위해서
utils.py에 분리했다.
전체 구현 코드는 GitHub repo에서 확인할 수 있다.
3) 사용 모델 & 데이터
- Bi-Encoder:
jhgan/ko-sroberta-multitask,dragonkue/multilingual-e5-small-ko-v2등 교체 실험 - Cross-Encoder:
snunlp/KR-SBERT-V40K-klueNLI-augSTS,BM-K/KoSimCSE-roberta등 교체 실험 - GrammarBook과 QA+PPL 후보는 팀장님이 준비해주신 데이터를 그대로 사용하기로 하였다.
4) Dual Encoder 구조 비교 (SDE vs ADE)
Dual Encoder를 설계할 때, 질문 인코더와 문서 인코더를 같은 파라미터로 공유할지(SDE), 아니면 분리할지(ADE)는 중요한 선택지다.
사실 처음에 듀얼 인코더 관련 공부를 하면서 이 내용을 확인하고 “우리 데이터에는 어떤 인코더를 써야할까?”라는 고민이 무척이나 많았다.
일단 공부한 내용을 정리해보면 다음과 같다.
두 가지 주요 구조
- Siamese Dual Encoder (SDE)
- 두 인코더가 완전히 동일한 파라미터를 공유
- 구조가 단순하고 질문/문서 도메인이 유사할 때 강력한 성능 발휘
- Asymmetric Dual Encoder (ADE)
- 질문 인코더와 문서 인코더가 서로 다른 파라미터를 가짐
- 입력 데이터 도메인이 이질적일 때 필요하지만, 성능은 일반적으로 낮음
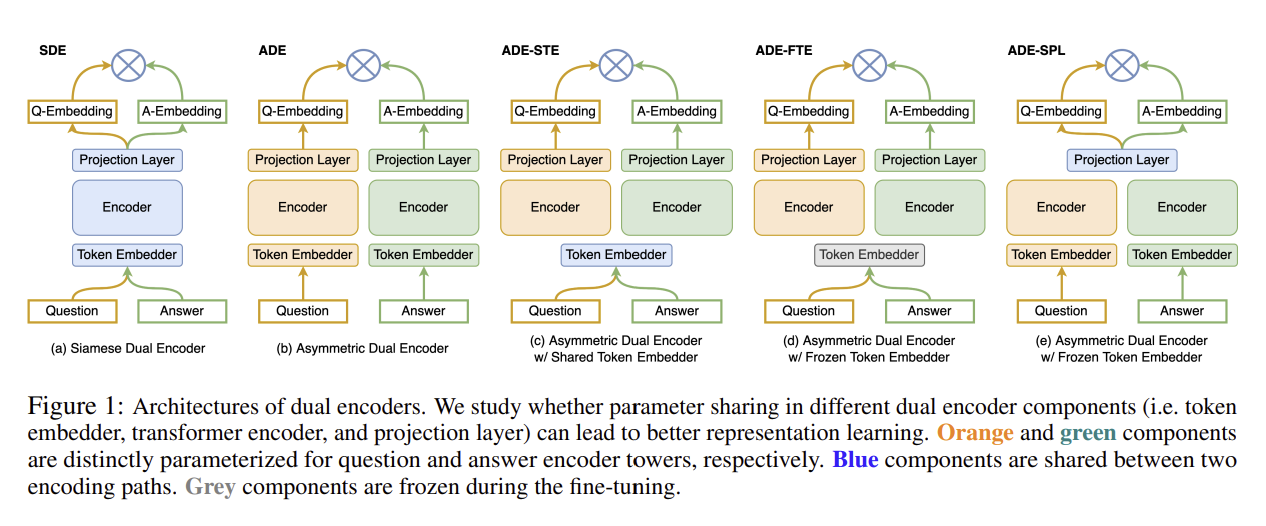
Figure 1. SDE와 ADE의 구조적 차이
적용 시 착안사항
- 질문 vs 문서 데이터가 유사하다면 → SDE 구조가 가장 간단하고 효과적
- 영역이 다르거나 분리 필요 → ADE 유지하되, Projection Layer만 공유(ADE-SPL)하는 방법이 현실적 절충안
구조별 특징 (논문 결과 요약)
| 구조 | 공유 계층 | 성능 요약 |
|---|---|---|
| SDE | 전체 공유 | 최고 성능 (대부분 QA 벤치마크에서 우세) |
| ADE | 없음 | 가장 낮음, 임베딩이 분리되어 retrieval 불리 |
| ADE-STE | 토큰 임베딩만 공유 | 개선 미미 |
| ADE-FTE | 토큰 임베딩 공유 + 고정 | 개선 미미 |
| ADE-SPL | 프로젝션 레이어만 공유 | SDE에 근접, 일부 과제에서는 더 좋음 |
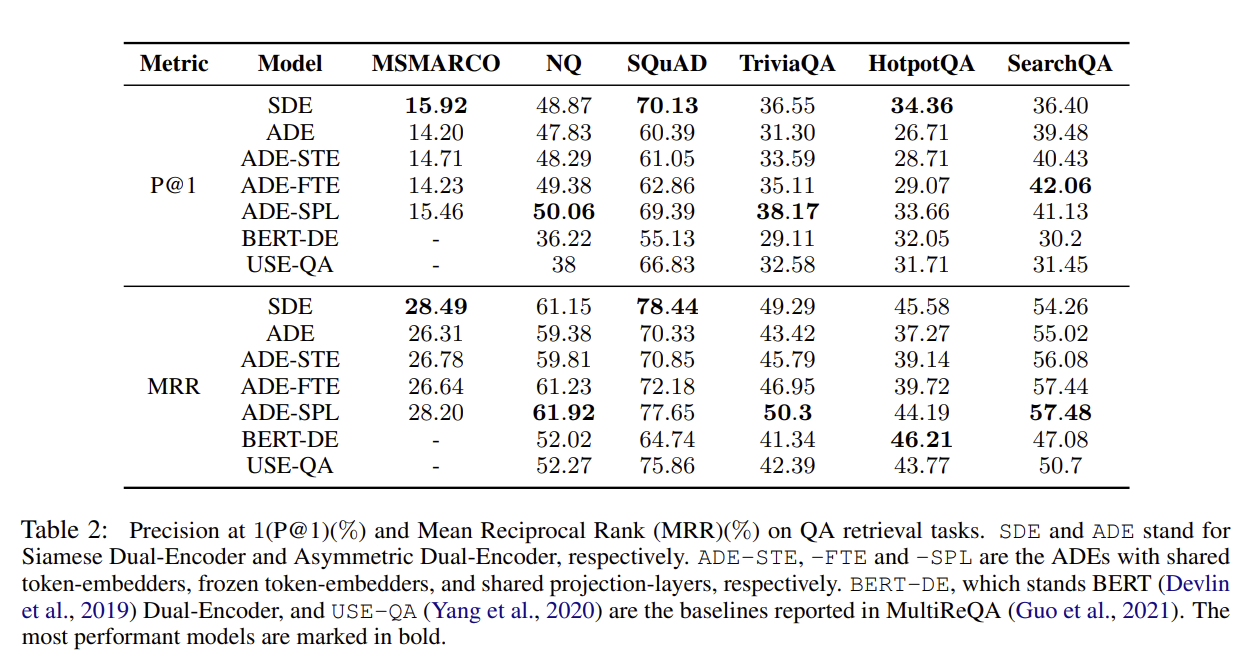
Figure 2. SDE vs ADE 성능 비교 (출처: Zhang et al., 2022)
Embedding 분포 분석
- SDE / ADE-SPL: 질문-답변 임베딩이 혼합되어 분포 → retrieval 친화적
- ADE: 질문/답변이 분리된 클러스터 → retrieval 성능 저하

Figure 3. Embedding 분포 (t-SNE 시각화, 논문 Zhang et al., 2022)
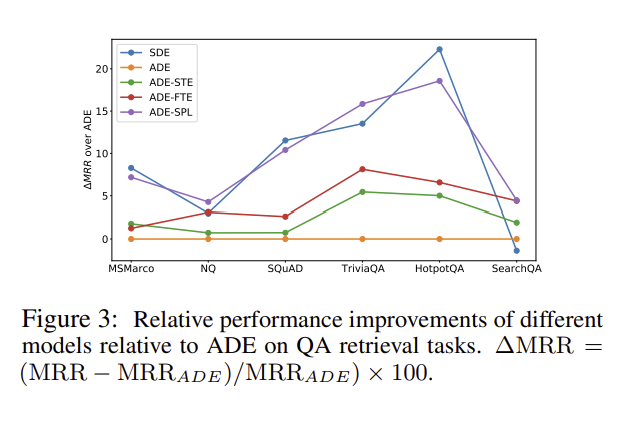
Figure 4. QA retrieval tasks Relative performance improvements (Relative performance 시각화, 논문 Zhang et al., 2022)
이번 프로젝트에서도 질문과 문맥이 모두 문법 규정이라는 동일한 도메인에 속하기 때문에, 인코더를 공유하는 구조(SDE)가 더 합리적이라고 판단했다.
따라서 나는 하나의 임베딩 레이어(SDE)만 사용하는 방향을 선택했다. 이는 실제 논문 결과에서도 SDE가 ADE보다 consistently 좋은 성능을 보였고, ADE-SPL만이 예외적으로 근접한 성능을 보인다는 점에 근거한다.
5) 실험 결과
결론적으로 실험을 돌려본 결과는 다음과 같다.
🔹 Test 1
1
2
BIENCODER="jhgan/ko-sroberta-multitask"
CROSSENCODER="snunlp/KR-SBERT-V40K-klueNLI-augSTS"
| 지표 | 값 |
|---|---|
| QA 문항 수 | 127 |
| Gold 문맥 Recall@30 | 89.8 % (114/127) |
| 평균 순위 | 7.6위 |
| Top-1 비율 | 41 % (52/127) |
Gold 분포
| 순위 | 횟수 |
|---|---|
| rank 1 | 52 |
| rank 2 ~ 5 | 13 |
| rank 6 ~ 10 | 20 |
| rank 11 ~ 20 | 19 |
| rank 21 ~ 30 | 10 |
- Top-10 85건(75%) 포함 → 리랭커가 대체로 적절한 재정렬
- Long-tail(>20위) 19건 존재 → 세밀한 구별력 보완 필요
Miss case 13건 (누락 10.2%)
- 합성/파생(맞춤법 제43~48항)에서 집중 누락 경향
🔹 Test 2
1
2
BIENCODER="dragonkue/multilingual-e5-small-ko-v2"
CROSSENCODER="BM-K/KoSimCSE-roberta"
| 지표 | 값 |
|---|---|
| QA 문항 수 | 127 |
| Gold 문맥 Recall@30 | 94.5 % (120/127) |
| 평균 순위 | 8.1위 |
| Top-1 비율 | 9 % (11/127) |
Gold 분포
| 순위 | 횟수 |
|---|---|
| rank 1 | 11 |
| rank 2 ~ 5 | 53 |
| rank 6 ~ 10 | 25 |
| rank 11 ~ 20 | 16 |
| rank 21 ~ 30 | 15 |
- Top-10 89건(≈70%) 포함
- Top-1 9%로 낮음 → 리랭커가 1위까지 밀어 올리는 힘은 약함
요약 비교
- Test1: Top-1 강세 / Recall 보통
- Test2: Recall 강세 / Top-1 약세
6) 배운 점 & 다음 계획
이번 공부를 통해 사전학습 Bi-Encoder + Cross-Encoder만으로도 빠르게 유의미한 Recall 확보 가능하다는걸 확인 가능했다.
다음 계획은 박사 과정 팀원분이 조언해주신 것에 따라 커스텀이 가능하게 nn.Module을 사용하여 구현 방식을 바꿔보기로 하였다.
그리고 우리의 데이터에 맞게 파인튜닝을 진행한 후 동일 평가셋으로 Recall@k/Top-1을 재측정 해볼 예정이다.